

1 At the supermarket
1.1 Number sequences
Imagine that you are at a modern supermarket and the cashier is processing the items from your basket or trolley. The electronic till (which is a form of computer) records each item that you have bought. Most items are scanned using a device that can read the barcode printed on the item.

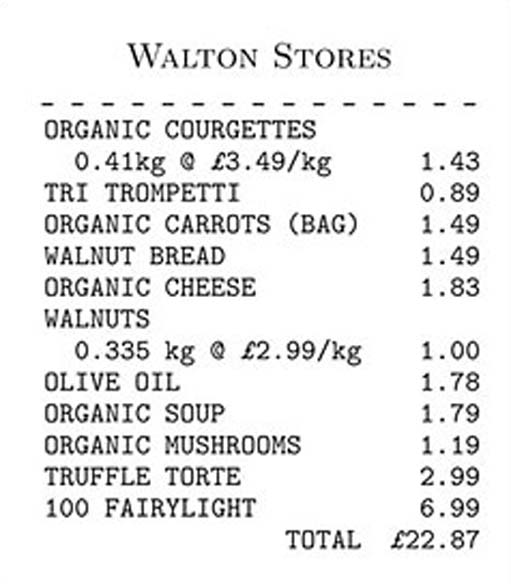
Items that need to be weighed (such as loose fruit and vegetables) do not have a barcode printed on them. Instead, the cashier looks up a different sort of code for these items and enters this manually at the till, together with the weight of the item purchased. If an error is made, the cashier may cancel the item just entered and try again. When all the items you have purchased have been processed, your final bill is calculated and you receive an itemised receipt (Figure 2).
Let us look a little more formally at some of the data that the supermarket computer system must store and use. As we do this, you will begin to get a flavour of the rigour that underpins the design of modern software. You will meet new vocabulary and concepts, try to get a general sense of what each new term means.
Each type of item stocked by the supermarket needs to be identified. As we have seen, this is done either using barcodes or, for weighed items, item codes of a different sort. Associated with each code is a variety of other item-related information. Perhaps the most obvious information is the price, and the description that appears on the receipt. (In the case of weighed items, the price is a unit price, giving the price per kilogram, for instance.) Other information associated with any item code might include the current stock level (so that new stock can be ordered as items are near to being out of stock), the name and address of the supplier, discount rates for multiple purchases, etc
Barcodes such as 5000119004048 can be interpreted as whole numbers. Whole numbers are called integers. Integers may be positive, negative or zero. (The codes for weighed items are also usually whole numbers.)
Prices and weights are not ordinarily presented as whole numbers. In Figure 2, the item price of walnut bread is shown as £1.49; the unit price of organic courgettes is £3.49 per kg and the weight of organic courgettes purchased is 0.41 kg (kg is the standard abbreviation for kilogram).
A number with a fractional part such as 1.49 is an example of a real number. The real numbers include numbers such as 3.497825 (and numbers such as √2, which cannot be expressed exactly as any fraction or decimal). Computers cannot represent such real numbers exactly. When dealing with a real number, we can only rely on a computer storing and manipulating an approximation of the number. Even though the extent of the approximation may seem small, this can present problems to the unwary software developer. To avoid problems here, we will represent prices as a whole number of pence, and weights as a whole number of grams. So, for example, the bill in Figure 2 includes a purchase of 335 grams of walnuts at 299 pence per kg.
As the items in a basket or trolley are scanned one after another, the till stores a sequence of codes. We use a precise notation to indicate a sequence. Suppose that the item codes scanned so far are 50773, 50412, 50330, 33777, 50773. If the codes were scanned in this order, then the till would store the sequence [50773, 50412, 50330, 33777, 50773]. If the same codes were scanned in a different order, then the till might store the sequence [50773, 50773, 50412, 50330, 33777]. Barcodes normally contain more digits. In our illustrative examples, we shall use shorter codes that are easier to read.
A sequence is a collection of items in a particular order. We shall write the items in a sequence between square brackets [ and ], and commas are used to separate the items in it (in other texts, you may see angled brackets 〈 and 〉 used to show a sequence, rather than [ and ]). These items are called the elements of the sequence. The order in which items appear in a sequence is important, so that [50773, 50412, 50330, 33777, 50773] is not the same as the sequence [50773, 50773, 50412, 50330, 33777]. Of course, the order in which the cashier checks your purchases does not matter in terms of the final cost. But, while the items are being entered, the order will often matter. For example, if an error occurs in scanning or weighing, the last item entered can usually be corrected using a ‘Cancel Last Item’ key on the till. Also, the itemised bill that you receive usually gives the items in the order in which they have been processed.
Item descriptions in Figure 2 include “ORGANIC SOUP” and “OLIVE OIL”. These descriptions are formed from characters that can be typed from a computer keyboard (possibly with the Shift key pressed). There are various points to note about characters. For example, upper- and lower-case versions of the same letter, such as ‘P’ and ‘p’, are different characters. A digit such as ‘5’ can be entered from the keyboard as a character, and it is vital to be clear that, in terms of its storage in computer memory, this is not the same thing as the number 5. This means that “SOUP”, for example, also forms a sequence. It is a sequence of characters, and could be written as [‘S’, ‘O’, ‘U’, ‘P’]. However, to do this would be tedious, since we will use sequences of characters frequently. So we often use the notation “SOUP”, just to make life easier! When we do this, we usually refer to the sequence of characters as a string.
Note that we have introduced a number of notational conventions. An individual character is written between single inverted commas, as in ‘P’ or ‘q’. Double inverted commas are used to show a sequence of characters such as “ORGANIC”. If we write out in full the string “ORGANIC COURGETTES 0.41kg @ £3.49/kg”, it is necessary to deal with the spaces between words. This use of double inverted commas only applies to sequences of characters. All other sequences are written using the square bracket notation introduced above. Spaces are characters like any others; they are obtained by pressing the space-bar on the keyboard. It is often desirable to indicate the space character explicitly by adopting a special symbol. We shall use ‘![]() ’. Thus, we may write [‘O’, ‘R’, ‘G’, ‘A’, ‘N’, ‘I’, ‘C’, ‘
’. Thus, we may write [‘O’, ‘R’, ‘G’, ‘A’, ‘N’, ‘I’, ‘C’, ‘![]() ’, ‘C’, ‘O’, ‘U’, ‘R’, ‘G’, ‘E’, ‘T’, ‘T’, ‘E’, ‘S’, ‘
’, ‘C’, ‘O’, ‘U’, ‘R’, ‘G’, ‘E’, ‘T’, ‘T’, ‘E’, ‘S’, ‘![]() ’, ‘0’, ‘.’, ‘4’, ‘1’, ‘k’, ‘g’, ‘
’, ‘0’, ‘.’, ‘4’, ‘1’, ‘k’, ‘g’, ‘![]() ’, ‘@’, ‘
’, ‘@’, ‘![]() ’,‘£’, ‘3’, ‘.’, ‘4’ ‘9’, ‘/’, ‘k’, ‘g’].
’,‘£’, ‘3’, ‘.’, ‘4’ ‘9’, ‘/’, ‘k’, ‘g’].
Imagine you are at the fifth till in the supermarket, and the data that constitutes your transaction is recorded by the supermarket's computer using the identifier till5. This is the name of an area in the computer's memory devoted to storing your transaction details. The data stored in till5 changes each time an item is scanned or entered, and so we refer to till5 as a variable. We call the data stored in the variable till5 at any moment in time the state of till5. Each time that the data stored by till5 changes, we say that the state of till5 has changed. You do not need to know anything about how the computer's electronic memory actually works.
These comments are not peculiar to the fifth till at the supermarket. The supermarket's computer stores data for each active till. The data for each till can be seen as a variable, and so needs its own identifier — such as till1, till2, and so on. Indeed, the term variable is used for any named area of computer memory, storing data that may change.
Now suppose that the variable till5 stores a sequence of barcodes. When the cashier starts a new transaction, no items have been entered, so the state of the variable till5 needs to start as a sequence with no elements, which we call an empty sequence and write as [ ]. If an item with code 50297 is then entered, then the state of till5 will change to [50297]. If an item with code 50152 is scanned next, then the state becomes [50297, 50152], and so on.
When a new item is recorded, the state of till5 changes, and changes in a way that is predictable. Specifically, the current state is changed by appending the newest item to the end of the sequence, giving a new state.
We have described the change of a till state in a way that is quite general. The description is not peculiar to the fifth till in the supermarket: it applies equally well to a transaction in progress at any till. Indeed, it describes a process that adds a new item to any variable storing data as a sequence.
| Item code | Item price (pence) |
|---|---|
| 33050 | 299 |
| 53151 | 440 |
| 77502 | 89 |
Now suppose the computer stores the prices of certain items as given in Table 1. To calculate the bill corresponding to purchases read by the cashier as [77502, 53151, 33050, 77502], we need to store the price associated with each item purchased. Let us assume that a second sequence is also being generated as each item is recorded, giving the price of the item. Suppose that this is stored as a variable price5. If the sequence of item codes were [77502, 53151, 33050, 77502], then the sequence of prices would be [89, 440, 299, 89]. Given this sequence, the total bill is obtained by simply finding the total of all the values in the sequence price5:
89 + 440 + 299 + 89 = 917 pence.
For simplicity, assume that there are no weighed items and no special offers.
This calculation does not change the state of the variable price5, but the value calculated certainly does depend upon the state of that variable.
Appending a new item at the end of a sequence, or adding a sequence of numbers, are both examples of the sort of processes that software needs to carry out time and time again. Recognising generality, and forms of data and processes on data that can be reused, are key skills in learning to design large and complex software systems.
Activity 1
Consider a process that changes the state of a variable storing a sequence by removing the last item from the sequence. So, for example, if the state of the variable was [22, 31, 53, 22, 13], then applying the process would change the state to [22, 31, 53, 22]. Suppose that this process is applied four more times. Write out the state of the variable after each application.
Discussion
The state starts as [22, 31, 53, 22]. After one more application of this process the state is [22, 31, 53]. If the process is applied again, the state becomes [22, 31]. If the process is applied again, the state becomes [22]. If the process is applied one more time, then the last item in the sequence is removed. We are left with a sequence containing no items, the empty sequence, which we write as [ ].
Since we use double inverted commas for strings, i.e. sequences of characters, we will use “ ” to denote the empty string in this course. In many computing texts, the symbol ξ is used.
Activity 2
How many characters are there in the string “I am it.”? Using the notational conventions introduced above for writing sequences and characters (including the space character), write this string out in full as a sequence of characters.
Discussion
This string includes eight characters in all, including two space characters and a full stop. Written in full, it is the following sequence of characters:
[‘I’,‘![]() ’,‘a’,‘m’,‘
’,‘a’,‘m’,‘ ![]() ’,‘i’,‘t’,‘.’].
’,‘i’,‘t’,‘.’].