

2.3 From ear to phoneme: the phonological problem
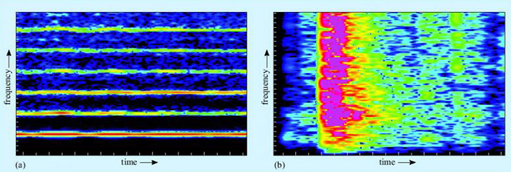
The phonological problem is the problem of knowing which units (words, calls) are being uttered. The speech signal is a pattern of sound, and sound consists of patterns of minute vibrations in the air. Sounds vary in their frequency distribution. The sound of a flute playing is relatively harmonic. This means that the energy of the sound is concentrated at certain frequencies of vibration. A plot of the energy of a sound against the frequency at which that energy occurs is called a spectrogram. A spectrogram for a flute's note is shown in Figure 3a. As you can see there are slim coloured bands, and black spaces in between. The coloured bands are the regions of the frequency spectrum where the acoustic energy is concentrated, whereas in the black areas there is little or no acoustic energy. The lowest coloured band corresponds to the fundamental frequency of the sound. This is where the most energy is concentrated, and it is the fundamental frequency which gives the sensation of the pitch of the sound. The higher bands are called the formant frequencies. In a ‘pure’ tone, their frequencies are mathematical multiples of the fundamental (in acoustics in general, they are also called overtones or harmonics, but in relation to speech, they are always called formants). The relative strengths of the different formants determine the timbre or texture of the sound.
SAQ 4
In terms of fundamental and formant frequencies, why might a violin, a flute, an oboe and a human voice producing the same note sound so different?
Answer
The fundamental frequency is necessarily the same in all cases, since the pitch of the note is the same. The relative strength of the different formants is the main source of the different qualities – thin, reedy, soft, full or whatever – of the notes.
In contrast to harmonic sounds are sounds in which the acoustic energy is dispersed across the frequency spectrum, like the box being dropped in Figure 3b above. These are experienced as noises rather than tones (it is impossible to hum them), and they appear on the spectrogram as a smear of colour.
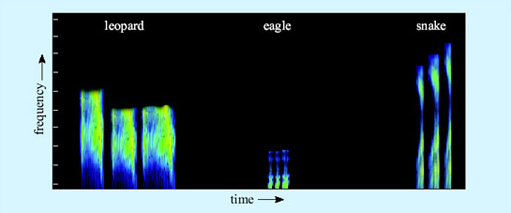
For the vervet monkeys, the phonological problem is not too difficult. There are only three major alarm calls, and their acoustic shapes are radically different and non-overlapping (Figure 4). They are also different from the other vocalisations vervets produce during social encounters. Thus the incoming signal has to be analysed and matched to a stored representation of one of the three calls.
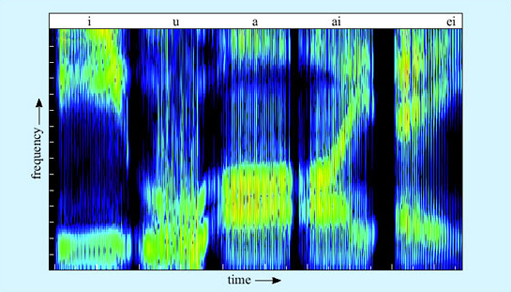
The human case is more complex. The first stage is to extract which phonemes are being uttered. Phonemes come in two major classes, consonants and vowels. Vowels are harmonic sounds. They are produced by periodic vibration of the vocal folds which in turn causes the vibration of air molecules. The frequency of this vibration determines the pitch (fundamental frequency) of the sound. Different vowels differ in quality, or timbre, and the different qualities are made by changing the shape of the resonating space in front of the vocal folds by moving the position of the lips and tongue relative to the teeth and palate. This produces different spectrogram shapes, as shown in Figure 5. (The conventions used in this chapter to represent spoken language are given in Box 1 below.)
Box 1: Representing spoken language
The spelling we usually use to represent English in text does not relate very systematically to the sounds we actually make. Consider, for example, the words farm and pharmacy. The beginnings of the words are identical to the ear, and yet they are written using different letters. The reasons for this are usually historical, in this case due to pharmacy coming into English from Greek. The letter r is also there as a historical remnant – the r in farm is now silent, but it used to be pronounced, and still is in some varieties of English, for example in South-West England and in Scotland.
For linguists it matters what sounds people actually produce, so they often represent spoken language using a system called the International Phonetic Alphabet (IPA). Sequences of speech transcribed in IPA are enclosed in slash brackets, / /, or square brackets, [ ], to distinguish them from ordinary text. Many of the letters of the IPA have more or less the same value as conventional English spelling. For example, /s/, /t/, /d/ and /l/ represent the sounds that you would expect. The IPA is always consistent about the representation of sounds, so cat and kitten are both transcribed as beginning with a /k/.
The full IPA makes use of quite a lot of specialised symbols and distinctions that are beyond our purposes here, so we have used ordinary letters but tried to make the representation of words closer to what is actually said wherever this is relevant to the argument. We have used the convention of slash brackets to indicate wherever we have done this, so for example, the word cat would be /kat/ and sugar would be /shuga/.
SAQ 5
Is the vowel of bit higher or lower in pitch than the vowel of bat?
Answer
There is no inherent difference in pitch (fundamental frequency) between bit and bat. You can demonstrate this by saying either of them in either a deep or a high pitched voice. The difference between them is in the relative position of the higher formant frequencies.
The relative position of the first two formant frequencies is crucial for vowel recognition. Artificial speech using just two formants is comprehensible, though in real speech there are higher formants too. These higher formants reflect idiosyncracies of the vocal tract, and thus are very useful in recognising the identity of the speaker and the emotional colouring of the speech. Some of the vowels of English have a simple flat formant shape, like the /a/ and /i/ in Figure 5 above. Others, like the vowels of bite and bait, involve a pattern of formant movement. Vowels where the formants move relative to each other are called diphthongs.
Consonants, in contrast to vowels, are not generally harmonic sounds. Vowels are made by the vibration of the vocal folds resonated through the throat and mouth with the mouth at least partly open. Consonants, by contrast, are the various scrapes, clicks and bangs made by closing some part of the throat, tongue or lips for a moment.
SAQ 6
Make a series of different consonants sandwiched between two vowels – apa, ata, aka, ava, ama, afa, ada, aga, a'a (like the Cockney way of saying butter). Where is the point of closure in each case and what is brought to closure against what?
Answer
apa, ama – The two lips together
ata, ada – The tip of the tongue against the ridge behind the back of the top teeth
aka, aga – The back of the tongue against the roof of the mouth at the back
ava, afa – The bottom lip against the top teeth
a‘a – The glottis (opening at the back of the throat) closing
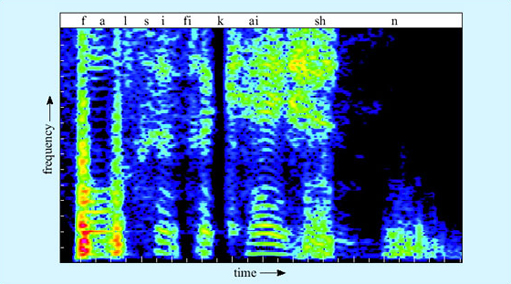
The acoustics of the consonants are rather varied. Some consonants produce a burst of broad spectrum noise – look for instance at the /sh/ in Figure 6. Others have relatively little acoustic energy of their own, and are most detectable by the way they affect the onset of the formants of the following vowel.
Phonemes make up small groups called syllables. Typically a syllable will be one consonant followed by one vowel, like me, you or we. Sometimes, though, the syllable will contain more consonants, as in them or string. Different languages allow different syllable shapes, from Hawai'ian which only tolerates alternating consonants and vowels (which we can represent as CVCVCV), to languages like Polish which seem to us to have heavy clusters of consonant sounds. English is somewhere in the middle, allowing things like bra and sta but not allowing other combinations like *tsa or *pta.
SAQ 7
Pause for thought: Why do you think language might employ a basic structure of CVCVCV?
Answer
Long strings of consonants are impossible for the hearer to discriminate, since identification of some consonants depend upon the deflection they cause to the formants of the following vowel. Long strings of vowels merge into each other. Consonants help break up the string of vowels into discrete chunks. So an alternation of the two kinds of sound is an optimal arrangement – after all, the babbling of a baby uses it.
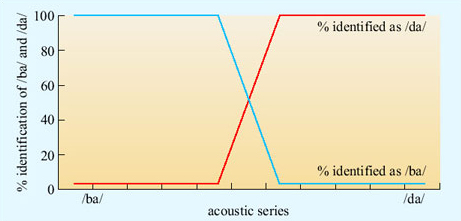
The task of identifying phonemes in real speech is made difficult by two factors. The first is the problem of variation. Phonemes might seem categorically different to us, but that is the product of our brain's activity, not the actual acoustic situation. Vowels differ from each other only by degree, and this is also true for many consonants. A continuum can be set up between a clear /ba/ and a clear /da/ (Figure 7). Listening to computer-generated sounds along this continuum, the hearer hears absolutely /ba/ up to a certain point, then absolutely /da/, with only a small zone of uncertainty in between. In that zone of uncertainty (and to some extent outside it), the context will tend to determine what is heard. What the listener does not experience is a sound with some /ba/ properties and some /da/ properties. It is heard as either one or the other, an effect known as categorical perception.
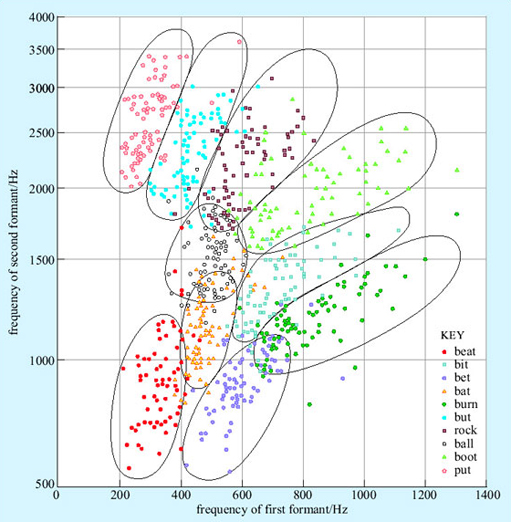
The hearer cannot rely on the absolute frequency of formants to identify vowels, since, as we have seen, you can pronounce any vowel at any pitch, and different speakers have different depths of voices. So a transformation must be performed to extract the position of (at least) the first two formants relative to the fundamental frequency. But that is not all. Different dialects have slightly different typical positions of formants of each vowel; within dialects, different speakers have slightly different typical positions; and worst of all, within speakers, the relative positions of the formants change a little from utterance to utterance of the same underlying vowel (Figure 8). The hearer thus needs to make a best guess from very messy data.
This is made more difficult by the second factor, which is called co-articulation. The realisation of a phoneme depends on the phonemes next to it. The /b/ of bat is not quite the same, acoustically, as the /b/ of bit. We are so good at hearing phonemes as phonemes that it is difficult to consciously perceive that this is so, except by taking an extreme example, as in the exercise below.
SAQ 8
Listen closely to the phoneme /n/ in your own pronounciation of the word ten, in the following three contexts – ten newts, ten kings, ten men. Say the words repeatedly but naturally to identify the precise qualities of the /n/ in each case. Are they the same? If not, what has happened to them?
Answer
You will probably find that the articulation of the /n/ is ‘dragged around’ by the following consonant – towards the /ng/ of long in ten kings, and towards /m/ in ten men. If this is not clear, try saying ten men tem men over and over again (or alternatively ten kings teng kings). You soon realise that there is no acoustic difference whatever between the two phrases. This is an example of assimilation, a closely related phenomenon to co-articulation.
Co-articulation makes the task of the hearer even harder, because they have to undo the co-articulation that the speaker has put in (unavoidably, since co-articulation is unstoppable in fast connected speech). A sound which is identical to an /m/ which the listener has previously heard might actually be an /m/, but it might equally be an /n/ with co-articulation induced by the context. An upward curving onset to a vowel might signal a /d/ if the vowel is /e/, but a /b/ if the vowel is /a/. Yet the listener does not yet know what the vowel is. They are having to identify the signal under multiple and simultaneous uncertainties. Speakers use their expectations about what is to follow to resolve these uncertainties.
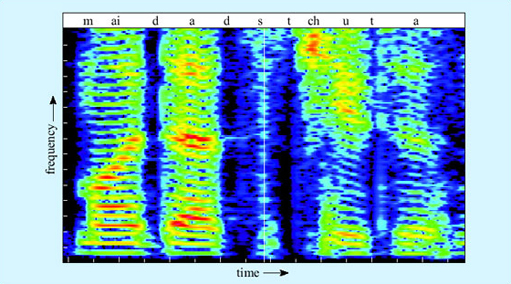
Other problems arise in the extraction of words from sound. Consider Figure 9, which is part of the spectrogram of the author producing sentence (1). Our brains so effortlessly segment speech into words that we are tempted to assume that the breaks between the words are ‘out there’ in the signal. But as you can see, there are no such gaps in speech. There are moments of low acoustic intensity (black areas), but they do not necessarily coincide with word boundaries. Co-articulation of phonemes can cross word boundaries.
Strings of phonemes have multiple possible segmentations. My dad's tutor could be segmented, among many other possibilities, as:
-
(7a) [my] [dads] [tu] [tor]
-
(7b) [mide] [ad] [stewt] [er]
-
(7c) [mida] [dstu] [tor]
The signal rarely contains the key explicitly. The hearer can exploit knowledge of English phonological rules, for example to exclude (7c) on the grounds that it contains an impossible English syllable. Beyond that, knowledge of words must come into play. Segmentation (7b) is phonotactically fine, but doesn't mean anything in English. Our segmentations always alight on those solutions that furnish a string of real words, so (7a) would be chosen. If your name was (7b), you would have extreme trouble introducing yourself, however clearly you spoke, whereas any segmentation containing whole words is much easier to understand.
SAQ 9
Can you see any problems that might arise with achieving either phoneme identification before segmentation into words, or segmentation into words before phoneme identification?
Answer
As we saw above, identification of phonemes often depends upon the word context. On the other hand, segmentation into words depends upon identifying the phonemes. In short it seems likely that neither can always be achieved prior to the other.
We will consider models of how the brain actually does it in Section 3.