

5 Representing text in binary
Most modern systems for encoding text derive in part from ASCII (American Standard Code for Information Interchange, pronounced ‘askee’), which was developed in 1963. In the original ASCII system, upper-case and lower-case letters, numbers, punctuation and other symbols and control codes (such as a carriage return, backspace and tab) were encoded in 7 bits. As computers based on multiples of 8 bits (or a byte) became more common, the encoding system became an 8-bit system, and so could be expanded to include more symbols.
When binary numbers were assigned to each character in the original ASCII system, careful thought was given to choosing sequences of values for the characters of the alphabet and numerals that would make it easy for a computer processor to perform common operations on them. (These encodings were preserved in the 8-bit system by simply padding out the leftmost bit with a 0.)
To illustrate, let’s look at the 8-bit encoding of some of the lower-case and upper-case letters of the English alphabet, shown in Table 1.
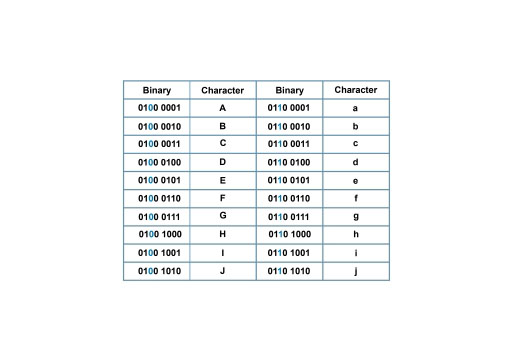
Notice that the ASCII values for corresponding upper-case and lower-case characters always differ by one bit, shown in blue. This means that converting from upper case to lower case (a very common manipulation of text) is simply a matter of ‘flipping’ one bit.
The original ASCII codes are suitable for representing North American English, but do not allow for other languages that use Latin characters with diacritics, nor for languages that do not use a Latin alphabet at all. This was a major problem with the ever more widespread use of computers and processors. It took a long time for an acceptable international standard to emerge but since 2007, the standard encoding system for characters has been Unicode Transformation Format-8 (UTF-8) which uses a variable number of bytes (up to 6) to encode characters in use across the world. However, in order to maintain backward compatibility, the original 127 ASCII codes are preserved in UTF-8.
In the next section, you will look at numbers.