
1 Overview
1.1 Human genetics and health issues
1.1.1 Inheritance of characters
Imagine you have found some old family photograph albums which span many generations. What are the distinctive family features, or characters, that demonstrate the relatedness of individuals? In other words, what characters do they have in common? For example, they might have brown eyes, a white forelock in their hair, ears that are closely attached to the head, that is, without lobes. But you will also notice the striking differences between related individuals. For example, they may differ in height or hair texture. Some similarities and differences extend to characters that are not visible. For example, individuals may share the same blood group, or they may differ in the amount of cholesterol (a type of fat) circulating in the blood.
Working back through the albums, consider those individuals who have passed away and the reasons for their deaths, such as cancer or heart disease. All these visible and invisible characters of an individual and also their medical histories are governed by their genes and the environments in which they have lived.
Genes are units of inheritance. Our characters — the structure and appearance of an individual, such as blue or brown eye colour — depend on the functions of genes. Genes also contribute to a person's behaviour and health, including susceptibility to certain diseases, such as heart disease. How do genes influence our individual characters and the type of disease each of us might develop? How are genes transmitted from generation to generation? Where are genes located? These are some of the questions that this course sets out to answer.
The following video clip provides a brief introduction to genetically inherited characteristics.
You have selected this course almost certainly because you are interested in learning more about human genetics — the study of genes — and thus you may already be familiar with some of the scientific terms used. One of our aims in writing this course is to put you in a stronger position when you read about the science of genetics and listen to informed debates about modern techniques of manipulating genes, by increasing your understanding of the concepts and issues involved.
Many thousands of genes have been discovered, including many that have roles in disease. These genes are scattered throughout the human genome. But what is the human genome? The physical appearance of the bulk of the human genome is 46 long, thin structures known as chromosomes. The genome of all individuals (with a few exceptions) looks like that in Figure 1.1. It is along the length of each chromosome that the genes are located. The term genome is a combination of the two words ‘gene’ and ‘chromosome’.
Chromosomes are built up from a remarkable substance called DNA (which stands for deoxyribonucleic acid). DNA is breathtakingly simple in structure and yet capable of directing the way we grow, reproduce and survive; hence it is often referred to as the genetic blueprint — the plan — of human life. Since genes are part of chromosomes they too are composed of DNA, which is why DNA is referred to as the genetic material.
The following video clip contains a little more information about DNA.

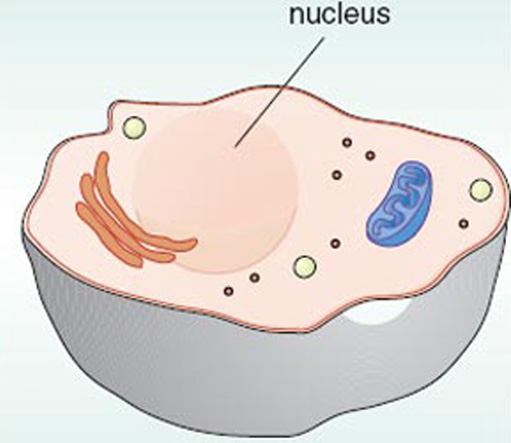
Where, within the human body, are the chromosomes located? We, like many different types of organism, are composed of many millions of millions of cells; indeed, the cell is often referred to as the ‘unit of life’. Cells are too small to be seen with the naked eye, but if you were to take a scraping from the inside of your cheek and look at it under a microscope you would see some cells, like the one in Figure 1.2. The important feature about cells for the human genome is the large structure called the nucleus, because it is inside the nucleus that the chromosomes are found. Within the nucleus of every cell in the human body (with a few exceptions) is a copy of the human genome. This adds up to a huge amount of DNA within any single individual.
In order to understand more about genes and the rest of the genome, in 1991 a formal programme, the Human Genome Project, was established to discover all the genes along each chromosome and to sequence the entire length of the human genome. On Monday 26 June 2000, scientists announced world-wide that they had completed a rough or first draft of the sequence of the human genome. The powerful headlines shown in Figure 1.3 were the way that some British newspapers captured the attention of their readers, on or around that date. Is the Human Genome Project ‘the breakthrough that changes everything’ (Figure 1.3), and, if so, how will it? Does the draft sequence really have implications for ‘every person on the planet’ or just for scientists and doctors?

What do the words in the headline ‘sequence of the human genome’ (Figure 1.3) mean? DNA contains information in a code that can be written in a four-letter language, A, C, G and T, in which each letter represents a different chemical (adenine, cytosine, guanine and thymine). Like all codes, the one in DNA carries information or instructions; in this case, ones that direct the growth and survival of each individual. Like every letter in each word in this sentence, to be meaningful, the letters A, C, G and T have to be in the correct order or sequence in each gene. The Human Genome Project involves identifying each of these letters in the correct sequence for each chromosome in turn for the whole genome.
Before we go any further, we should try to gain some appreciation of the immense scale of one copy of the human genome and hence the phenomenal scope of the task that faced the Human Genome Project. The human genome comprises approximately six billion, 6 000 000 000, letters (chemicals) of A, C, G and T, joined together in pairs, i.e. 3 000 000 000 pairs, in a linear sequence along the length of the chromosomes. In order to appreciate the scale of this, consider the following data. The typeface of a typical book enables approximately 5000 letters to be printed on one page. Thus the sequence of the human genome would take a total of 600 000 pages and fill about 3000 books. The project was made possible only by a large number of staff working in a substantial number of laboratories and, importantly, by database technology of computers. Each computer is linked to the internet, on which the results are published world-wide for free with no restrictions on their use or distribution.
By June 2000, the Human Genome Project had determined about 85% of the sequence of the four letters with about 99.9% accuracy. The figure of 85% was chosen as the point at which the genome would have scientific and medical value; hence the announcement on 26 June 2000 of the rough draft. By February 2001, about 90% of the sequence had been determined. But note that these drafts were far from perfect, containing many gaps. Since these initial publications, further sequencing has produced a more complete and accurate sequence so that by 2003 very few gaps and errors remained in the then published sequence. Most of these uncertainties have now been resolved. The ultimate goals are to produce a completely finished sequence by filling in the remaining gaps and perfecting the accuracy, and to understand and interpret fully all the details of the genome sequence including the genes it contains.
Let's return to June 2000. Our understanding of the human genome did not begin on this date; in fact, we had been learning about it, bit by bit, throughout the whole of the 20th century. The study of genes began in 1900 when it was shown that genes govern inheritance in many different creatures. In 1907 it was shown that the same patterns of inheritance could account for the transmission of eye colour in humans. However, not until 1953 was the structure of DNA deduced by Watson and Crick. Hence, most of this course will consider aspects of genetics and the genome that were understood long before the publication of the first draft of the human genome.
Human genetics is a huge topic. It would be possible to write a whole course that focused on just one aspect of it. However, our goal in this course is to introduce not only the science, but also some of the health issues generated by the study of genes. The science deals with the structure and function of the genome within each individual and the medical aspects such as disease genes and gene therapy. Although there are thousands of genes, some with very complicated names and functions, we discuss only a few straightforward but representative examples in order to demonstrate the basic principles.
The health issues include, for example, DNA testing for the presence of genes related to specific diseases. An issue is a topic that can always be considered from more than one point of view or perspective. For example, if the fetus of an expectant mother tested positive for a debilitating genetic disease, she might be confronted with the choice of a termination or having an affected child. The expectant mother's point of view and her partner's might be very different from that of the medical profession or society in general. Hence, health issues, in turn, raise social and ethical issues.