

3.5 MPEG audio layer 3 (MP3)
In connection with frequency masking, we said that the masked sound B in Figure 3.5 did not need to be encoded. You might wonder how sounds can be selectively encoded if others are present at the same time. The answer is by splitting the audio band into sub-bands which are encoded separately. If a masked sound occupies a different sub-band from a masking sound, one can be ignored and the other encoded.
Figure 3.7 shows the elements of the creation of an MP3 audio file. The source input is generally assumed to be an audio data stream from either a CD (fs = 44.1 kHz) or studio-recorded material (fs = 48 kHz). The signal is filtered into 32 critical frequency sub-bands that are designed to reflect the way the ear perceives sounds.
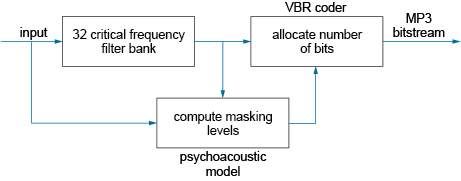
The 32 critical sub-bands are sampled separately, yet this does not increase the total number of samples beyond what would be required if the audio band were not split into sub-bands. Sub-bands typically have a width of 750 Hz, for which the sampling theorem requires a minimum sampling rate of 2 × 0.75 kHz = 1.5 kHz. Therefore, across the 32 sub-bands, the minimum number of samples per second must be 32 × (1.5 × 103) or 48 × 103. This is exactly the same as for a single band with a total bandwidth of 32 × 0.75 kHz = 24 kHz, for which the sampling theorem requires the minimum sampling rate to be 48 kHz.
Once the source signal has been split into critical sub-bands, the next step is to determine the amount of masking in each sub-band and its effect on adjacent bands – the so-called mask-to-noise ratio (MNR). This makes extensive use of the two psychoacoustic masking effects of the ear discussed above to govern the appropriate quantisation levels to be used in each different frequency sub-band. Collectively these define the masking threshold, which determines which frequencies will and will not be coded.
If the signal level in a sub-band is below the masking threshold, it is not encoded; if it is above the threshold, it will be coded using variable bit-rate coding (VBR). In VBR, the number of bits allocated to represent each frequency component is based upon the level of quantisation noise. In digital audio, the S/N ratio is approximately equivalent to ~6 dB bit−1 so the more bits allocated the higher the S/N ratio.
As an example, Table 3.1 shows the output levels of the first 12 critical sub-bands at a specific instant for an MP3 encoder. The output levels indicate the extent to which the level in any particular sub-band exceeds the threshold of hearing in that sub-band. If the output level were 0 in any sub-band, encoding would not be required in that sub-and because the output level would be on the threshold of audibility.
| Critical Sub-band | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Output level/dB | 18 | 14 | 42 | 58 | 12 | 5 | 10 | 8 | 6 | 1 | 4 | 2 |
Sub-band 4 has a high output level of 58 dB. Suppose this produces an effective masking threshold of 16 dB to sub-band 5. As 16 dB exceeds sub-band 5’s output level of 12 dB, sub-band 5 does not need to be encoded in the time period covered by these output levels.
Activity 3.3 Self assessment
Suppose sub-band 4 produces an effective masking threshold of 20 dB to sub-band 3. Does sub-band 3 need to be encoded?
Answer
The output level of sub-band 3 is 42 dB, which is above the masking threshold of 20 dB provided by sub-band 4, so this sub-band needs to be encoded.