Use 'Print preview' to check the number of pages and printer settings.
Print functionality varies between browsers.
Printable page generated Friday, 3 May 2024, 7:48 PM
Sampling (human health)
Introduction
To generate data on AMR in surveillance programmes or research studies, we first need to make decisions about how, where and from which entities (individuals or groups) to collect data. This is known as ‘sampling’.
This module will focus on sampling for AMR surveillance in human health, but will also draw comparisons to animal health, where relevant, to emphasise the importance of One Health approaches in tackling AMR.
After completing this module, you will be able to:
- describe the purpose of sampling individuals for AMR surveillance
- explain what factors need to be considered when choosing which individuals to sample for AMR surveillance
- recognise the lists of priority pathogens suggested for sampling in individuals
- list the steps involved in sampling individuals for AMR surveillance
- explain the common problems associated with identifying sampling frames and how they can be addressed.
Activity 1: Assessing your skills and knowledge
Before you begin this module, you should take a moment to think about the learning outcomes and how confident you feel about your knowledge and skills in these areas. Do not worry if you do not feel very confident in some skills – they may be areas that you are hoping to develop by studying these modules.
Now use the interactive tool to rate your confidence in these areas using the following scale:
- 5 Very confident
- 4 Confident
- 3 Neither confident nor not confident
- 2 Not very confident
- 1 Not at all confident
This is for you to reflect on your own knowledge and skills you already have.
1 Sampling basics
In this section we consider the basics of sampling: why and how to do it.
1.1 Why do we need to sample?
Have you ever taken part in a census, such as a national human population census? A census involves collecting data from every single unit (such as a human, animal, farm) in the population. Conducting a true census is a very resource-intensive activity. What happens if we would like to answer a question such as:
‘How frequently is resistance to a particular drug (e.g. methicillin) identified in Staphylococcus aureus isolated from hospital inpatients?’
Is it necessary to collect data on every single inpatient in a country to answer this question? In most cases, it is impractical to conduct a census, especially when we need to collect specimens, such as blood, urine or faecal samples, from every single person in a population.
Fortunately, for the majority of research or surveillance, it is not necessary to conduct a census. Instead, we can select an appropriate sample of subjects from the population. Sampling allows us to make inferences about a larger population. But we can’t just pick any people we happen to find and expect that this ‘sample’ allows us to make inferences (apply the findings) to the entire population; instead, there are several steps we have to go through to ensure that our sample is representative (accurately reflects the characteristics) of the broader population that we are interested in. Going through these steps is the focus of this section.
1.2 Sampling terminology
How can we determine what constitutes an ‘appropriate’ sample? It is helpful to introduce some terminology as we go through the steps in selecting a sample.

First, we need to identify the population in which we are interested – this is known as the ‘
Activity 2: Understanding sampling
Can you think of a population you are familiar with or interested in? (If not, try this example: imagine you have access to data on patients presenting to primary healthcare facilities with symptoms of urinary tract infections in the state, province or region where you work.)
Use the space below to answer the following questions:
- Can you identify the target population?
- Now think about the source population you might select. Can you imagine a possible study sample for this source population?
- Finally, note the possible sampling unit.
Discussion
How did you do with this activity?
If you chose to use the example provided, you might have identified that the target population could be all patients presenting to primary healthcare facilities with symptoms of urinary tract infections in your country. Your source population could be patients in your state or province. For your study sample, you may select a number of primary healthcare facilities from the chosen state or province (for example, 30 facilities), and then select all individual patients who present with symptoms of urinary tract infection. The sampling unit is likely to be an individual patient.
1.3 Sampling and validity
Why is it important to describe and identify these sampling parameters?
Here, we need to think about the ‘validity’ of sampling: how well a measurement represents the true situation. If you have already completed the Fundamentals of data for AMR module, you may recall that the concepts of
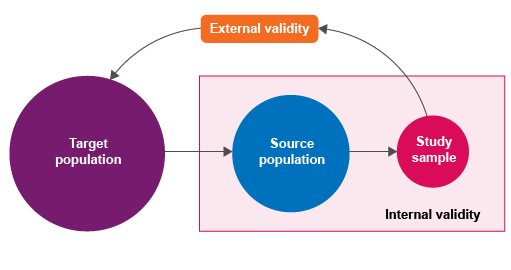
Epidemiological principles of sampling in animal populations are the same as the principles applied to sampling in human populations. In animal health, it is similarly necessary to define the target population, the source population, the study sample and the sampling unit. In animal health, a flock, herd or other group might be the lowest-level sampling unit: this is because in a herd, all the animals are in the same physical area and exposed to identical risk factors. By comparison, an individual is the most common lowest-level sampling unit in human health.
Activity 3 has an example of this.
Activity 3: Extracting useful sampling information
Read the following abstract from a study describing surveillance of AMR in bacteria causing urinary tract infections (UTIs) in Indonesia (Sugianli et al., 2017). Use the space below to identify the target population, source population, study sample and sampling unit.
Objectives: UTIs are a common reason for empirical treatment with broad-spectrum antibiotics worldwide. However, population-based antimicrobial resistance (AMR) prevalence data to inform empirical treatment choice are lacking in many regions, because of limited surveillance capacity. We aimed to assess the prevalence of AMR to commonly used antimicrobial drugs in Escherichia coli and Klebsiella pneumoniae isolated from patients with community- or healthcare-associated UTIs on two islands of Indonesia.
Methods: We performed a cross-sectional patient-based study in public and private hospitals and clinics between April 2014 and May 2015. We screened patients for symptoms of UTIs and through urine dipstick analysis. Urine culture and susceptibility testing were supported by telemicrobiology and interactive virtual laboratory rounds. Surveillance data were entered in forms on mobile phones.
Results: Of 3424 eligible patients, 3380 (98.7%) were included in the final analysis, and yielded 840 positive cultures and antimicrobial susceptibility data for 657 E. coli and K. pneumoniae isolates. Fosfomycin was the single oral treatment option with resistance prevalence E. coli and K. pneumoniae in community settings. Tigecycline and fosfomycin were the only options for treatment of catheter-associated UTIs with resistance prevalence K. pneumoniae.
Conclusions: Patient-based surveillance of AMR in E. coli- and K. pneumoniae-causing UTIs indicates that resistance to the commonly available empirical treatment options is high in Indonesia. Smart AMR surveillance strategies are needed to inform policy-makers and to guide interventions.
Discussion
How did you find this exercise? Was there enough information available in the abstract to complete this activity?
The target population is the population who have community- or healthcare-associated UTIs in Indonesia – this is the population to which the authors extrapolate their findings in the conclusions of the abstract. You should reflect on whether you agree with the authors that this is an appropriate target population, considering the study was conducted on only two islands in Indonesia.
The source population is the patients with UTIs attending public or private hospitals and clinics in two islands in Indonesia between April 2014 and May 2015. The source population is estimated to be 3424 eligible patients.
The study sample is 3380 patients, which is 98.7% of the source population.
The sampling unit is a patient with a UTI.
2 Sampling frames
We now know that in order to sample from a population, we need to first identify the target population and the source (study) population. We then select the study sample. But how do we identify sampling units that form part of the source population? We need a
A sampling frame might be a list of all of the hospitals in the province(s) selected as the source population, along with a list of all the patients being treated at these hospitals (either as inpatients resident in hospital or outpatients attending walk-in clinics, depending on the topic of interest) in a defined time period. Note that because sampling frames include identifying information such as names and addresses, extra attention must be paid to ensuring that this information is stored and accessed securely by authorised members of the research team or surveillance programme (see the Legal and ethical considerations in AMR data module).
Because sampling frames constitute a data-collection process, they are subject to the same risks of error and bias as all other AMR-related data collection and analysis (see the Fundamentals of data for AMR module for more information on error and bias). Most of the time, available sampling frames do not perfectly correspond to the actual source population: for example, a sampling frame for AMR surveillance might consist of a list of all antimicrobial susceptibility tests (ASTs) performed in laboratories on samples collected from hospitalised patients in a city. However, not all patients with resistant infections are sampled, or the sample may not be fully tested – that is, may not be tested against all the drugs of interest. Some hospitals have limited capacity and experience with collecting samples for bacterial isolation and AST. Some patients may decline to have their sample tested if they have to pay a fee for the laboratory test. In general, a sampling frame should include facilities, such as hospital sites, that account for at least 80% of the target population.
Activity 4: Identifying a sampling frame
Imagine that researchers would like to study the proportion of E. coli isolates that are resistant to specific antimicrobials among non-hospitalised patients with UTIs in their country (target population). Their study sample consists of all patients who present at selected primary healthcare facilities in one city over a three-month period.
Can you identify a possible source population and sampling frame for this study?
Discussion
The source population might include all non-hospitalised people with UTIs in one or more cities within their country, most of whom might go to a primary healthcare facility, but some might present to an emergency department in a hospital without being admitted, and some might seek care with alternative or traditional medicine providers.
A possible sampling frame they might have used is a Ministry of Health list of all primary healthcare facilities in the city where their study is conducted. They may have then selected primary healthcare facilities from this sampling frame, and enrolled all eligible patients at each of these facilities in their study.
A limitation you may have thought of is that there may not be an official register of alternative and traditional medicine providers.
In reality, sampling frames are not always available or complete, and therefore might not include all units in the source population, and so by extension are not representative of the target population. Examples include when there is a mix of public and private health facilities in an area, but only the public facilities are included in the sampling frame because it is more convenient to do so. For studies or surveillance of AMR or
Three potential solutions to achieving representative sampling when no adequate sampling frame exists are summarised below:
- Random geographic coordinates sampling: An online tool generates a series of randomly selected map coordinates that fall within certain geographic boundaries. Research teams then need to travel to each specific point (or as close as possible). Once the point is reached, sampling occurs as close to that point as possible. This might be used for sampling households in a village where no street addresses are used, for example.
- Systematic random sampling: The nth unit is selected from a series of units as each unit presents at sites (e.g. clinics) included in the sampling frame; for example, selecting every tenth patient who presents to a clinic. This is best performed when the total number of sampling units and the required sample size is known. The first unit to be selected should be decided by randomly generating a number. This method is also included as a sampling method in the next section.
- Stakeholder consultation: In some circumstances, it may be possible to develop a sampling frame through stakeholder consultation. For example, if there is no list of private (including traditional or alternative) health providers in a particular region, it may be possible to arrange a meeting with local leaders or community members and ask them to list the private practices they are aware of in the region. This approach is not perfect, but might be preferable to having no sampling frame at all.
3 Sampling methods
Once we have a sampling frame, or an appropriate alternative, we need methods to actually select the sampling units. There are many types; different academic sources report slightly different lists of sampling methods. However, the consensus is that all sampling methods are categorised into two groups: probability and non-probability methods.
3.1 Probability sampling
In probability sampling methods, every sampling unit within the population has the same (or known) probability of being selected. They allow for representative sampling (such that results can be generalised to the target population) and limit selection bias (see the Fundamentals of data for AMR module).
Probability sampling methods include the following:
- Simple random sampling: Where a sampling frame is available and is used to randomly generate a list of units to be sampled. This can be done manually (such as ‘pulling numbers out of a hat’) or using a random number generator to compile a list of sampling units.
- Systematic random sampling: Where every nth unit is selected as each unit presents (or appears). For example, this could involve selecting every fifth patient presenting at a primary healthcare facility included in the sampling frame. Both the sampling interval (what value n takes) and starting point (whether systematic sampling starts from the first, second, third or nth unit) should be selected randomly.
Video 1 summarises simple random sampling and systematic random sampling.
What is the main difference between simple and systematic random sampling?
A simple random sample is drawn using a random number generator, whereas a systematic sample starts at a random number, and then selects every nth unit.
There are important extensions to simple random sampling or systematic random sampling, to allow for probability sampling of primary, secondary and tertiary sampling units (as described in Section 1.2), as required. This includes the following:
- Multistage sampling: A random sample of primary units is selected, followed by a random sample of secondary units (and then tertiary, and so forth). For example, randomly selecting hospitals and then randomly selecting individuals in each hospital.
- Stratified random sampling: The source population is divided into mutually exclusive strata based on factors that may affect the outcome, such as geographic region. A known number of units are then randomly selected from each stratum.
- Cluster sampling: This is similar to multistage sampling, except that all sampling units are sampled in the final stage. That is, the hospitals are randomly selected, and then all patients in that hospital are sampled.
These different sampling methods can be combined. For example, stratified sampling can be included within a multistage sampling design.
Video 2 summarises two of the more advanced approaches to probability sampling. Watch the video and then answer the question below.
Which type of sampling divides the sample population according to their personal attributes?
Stratified sampling. By contrast, multistage sampling first divides the sample population according to their geographic area or similar variable, but not their personal attributes (such as age or gender).
3.2 Non-probability sampling
In non-probability sampling methods, sampling is done without determining a sampling unit’s probability of being sampled; that is, sampling units do not have an equal or known chance of being selected. Non-probability sampling methods should be avoided, as they introduce substantial bias, and greatly limit the applicability of the findings to the target population. There are two broad types of non-probability sampling methods:
Convenience sampling is the collection of easily accessible sampling units, such as individuals who present to the medical centre associated with the university where a research study is being conducted. It is common in AMR surveillance programmes and studies, but is highly prone to selection bias. For example, patients attending university medical centres, which often have a large number of different specialties, might have different characteristics from patients attending other types of facilities that offer a small range of specialties.
Convenience samples are typically poorly representative of the source population, and the findings from convenience samples cannot be generalised to the target population. Therefore, it is difficult to justify convenience sampling even though it is relatively commonly used. Efforts to identify and select from sampling frames should be promoted over convenience sampling.
In purposive sampling, units are deliberately selected because they have particular characteristics. Purposive sampling might be appropriate when dealing with a very rare disease or other health-related characteristic, as it can be impractical to use probability-based sampling in these circumstances. Instead, efforts are made to sample as many sampling units that have the disease or characteristic as possible. Purposive sampling is particularly relevant when characterising an emerging type of AMR. For example, shortly after the first reports of colistin resistance in humans, researchers in the Netherlands purposively sampled all travellers attending medical clinics included in a large study, who had recently returned to the Netherlands from an international location. They identified nine out of 1847 returning travellers who had acquired colistin-resistant E. coli infections (Arcilla et al., 2016). This type of study can inform whether surveillance or further research should be initiated, at which point sampling would be done using probability-based methods.
Video 3 summarises what you have learned so far.
What is the first step in sampling?
Defining the population of interest.
4 Sample size calculations
By this point, you have learned how to:
- describe the target population and source population
- identify a suitable sampling frame
- select a robust sampling method to select sampling units (e.g. individual patients) from the sampling frame.
A crucial step in finalising your sample is to determine how many sampling units should be selected. In this section, we will need to introduce some statistical concepts, as we use statistical calculations to define the minimum required sample size. However, there are also non-statistical considerations, which we will review first.
4.1 Non-statistical considerations for determining sample size
There are several non-statistical considerations when determining sample size. Firstly, in most cases, the availability of funding, time and human resources is a fundamental consideration when determining sample size. Secondly, when complete sampling frames do not exist, simple random sampling is impossible and alternative sampling strategies that may require higher sample sizes for equivalent precision are needed.
Most importantly, however, study objectives will ultimately determine the statistical parameters that are acceptable, and certain decisions need to be made before progressing to calculating the required sample size. In studies comparing AMR in one population to another, or temporal trends, one key consideration is the minimum difference that you want to detect. In general, the study should be able to detect the minimum ‘clinically meaningful’ difference. This is a clinical judgement, not a statistical calculation. For example, in a very large study, it might be possible to detect a 1% difference between two groups, but if only a 10% or higher difference would influence clinical practice or be important for public health, then a smaller sample in which a 10% difference can be detected is sufficient. Let’s review an example in Activity 5.
Activity 5: Minimum differences in practice
Figure 3 is taken from a study of antimicrobial use over a 12-month period on six cattle farms (labelled A to F) in the United Kingdom (Mills et al., 2018). Antimicrobial use (AMU) on farms is of interest to public health because most AMU globally occurs in agriculture, and there is a risk that resistant organisms can be transferred to humans from food animals. Even if your work is not focused on animal health, it is important to be aware of how AMR and AMU are measured and understood across all sectors, given the importance of One Health approaches to combatting AMR.

Each farm is represented as a separate bar in Figure 3. AMU is calculated using the
Knowing that Figure 3 represents AMU on six different farms, how might you describe the magnitude of difference in AMU between farms? Which differences might be large enough to be ‘clinically meaningful’? Use the space below to make notes of your conclusions.
Discussion
Figure 3 shows that Farm A reports no AMU, and Farm D reports very little. Farms C and E have very similar AMU, such that the difference between them might not be considered important. By contrast, Farm B has approximately double the AMU of Farms C and E, and AMU on Farm F is approximately six times higher than Farms C and E.
A twofold or greater difference in AMU might have implications for AMR prevention and control, and thus it would be ‘meaningful’ to detect such differences in a study or surveillance programme. In fact, we might consider the ‘minimum’ important difference to detect to be less than a doubling in the amount of AMU. Perhaps we might be concerned about any farm that had, for example, 30% more AMU than Farm D.
4.2 Statistical determinants of sample size
There are three key statistical parameters that have to be specified when determining sample size. In general, if a study sample is too small, the precision, confidence level and power of a study will fall short. This means you can’t reliably generalise the findings from your sample to the target population. Therefore, you need to understand and decide on appropriate values for each of these parameters in order to calculate the minimum sample size required.
For example, say that researchers want to determine the prevalence of resistance to oxytetracycline in E. coli isolates sampled from poultry farm workers who are potentially exposed to resistant isolates through their occupational contact with animals. The researchers plan to use an appropriate probability sampling strategy to select a representative sample of farms and individual workers. They decide they want their study results to be within 5% of the true prevalence (+/– 5%).
What is their desired precision?
Their desired precision is 0.05.
The
For example, say that researchers want to compare use of third-generation cephalosporins (3GCs) in Canadian and Australian hospitals. They are planning on using a probability sampling strategy to select a representative sample of hospitals in both countries. If a difference in use between the two countries is detected, they want to be 95% confident that this is because a difference truly does exist. What this means is that if the study shows a difference between the two countries, there is still a 5% probability that the difference found is due to chance (or luck) alone. For example, if all the Australian hospitals with high levels of 3GC use and all the Canadian hospitals with low levels of 3GC use happened to be selected, the results could suggest a difference that doesn’t actually exist.
The
4.3 Choosing a sample size calculator
To make life easier when designing a study there are several sample size calculators available online, including Epitools and Sample Size Calculators. Which sample size calculator to choose depends on the objectives of a study. Many AMR studies aim to estimate a single proportion, such as the proportion of isolates that are resistant to a particular drug. Some also compare two proportions, for example the number of resistant isolates in patients in one region compared to another region. Similarly, AMU studies might aim to measure the total amount of AMU, or compare AMU between hospitals. There are appropriate sample size calculators available for both of these objectives.
In addition to specifying the desired precision, confidence level and power to calculate a sample size, you may also have to provide values for other parameters. For example, to estimate the sample size required for a study comparing two proportions, you need to provide an input value for the proportion in the baseline (or control) population, and an input value for the proportion in the comparison population. This is where it can be helpful to think about the minimum clinically meaningful difference you wish to detect.
Activity 6: Sample size calculations in practice
Let’s use an online statistical calculator to calculate the sample size for a study comparing two proportions.
Imagine you wish to compare the prevalence of multidrug-resistant Klebsiella pneumoniae isolates in patients with UTIs in two neighbouring regions. You know from a previous study that the prevalence of multidrug resistance in K. pneumoniae isolates from one of the two provinces is around 50%. You’re not sure about the equivalent figure in the second province, but you are concerned that it is higher than in the first province. You decide it is important to be able to detect a prevalence of multidrug resistance of at least 55% in the second region, to test your suspicions. You would like your study to have a confidence level of 95%, and a power of 90%.
Using this Epitools online calculator, calculate the minimum sample size required to detect a difference in multidrug resistance prevalence between the two provinces. Don’t change the default values for ‘ratio of sample sizes’, or ‘use of 1 or 2 tailed test’ (which should be set at 1, and 2-tailed respectively) – these concepts are beyond the scope of this module.
Hint: remember that a proportion is a decimal between 0 and 1, so 50% is expressed as 0.5. You usually need to enter proportions, not percentages, when calculating sample sizes.
Fill in your values in the calculator and click on ‘Submit’. Use the space below to make notes on what you have done, and on the outcomes of the calculation. Are you surprised by the size of the sample needed to answer your experimental question?
Discussion
The total required sample size is 4268 isolates. This means you would need to collect samples from at least 2134 patients in each province. In practice, more patients may need to be sampled than calculated, to compensate for potential issues such as loss of collected samples, issues with sample transport, failure to isolate K. pneumoniae from some of the collected samples, and so on. This type of consideration is often described as adjusting for the anticipated ‘dropout rate’ of the study. The size of the required sample is likely to have resource implications that need to be considered before the decision is made to proceed.
4.4 Adjusting statistical parameters to suit constraints
In Activity 6, you calculated a sample size for a given set of statistical parameters. However, you may have noticed that the required sample size is quite large. In general, you should always aim to match your resources to the required sample size. That is, if the required sample size is large, endeavour to seek enough funding or capacity to achieve this sample size.
However, key statistical parameters can be altered from an ideal value to something less-than-ideal in order to achieve a more practical sample size that is sufficient (if not perfect) for addressing the research topic or surveillance objective. Reducing precision, confidence level or power, or increasing the minimum difference to detect, will lead to lower sample size requirements.
Note though that in practice, confidence level is rarely set below 90%, and power is rarely set below 80%. As a general guide, you should aim to have 95% confidence, 80% power and 5% precision (where relevant), as well as a minimum detectable difference that is truly clinically meaningful (which might be as small as 5% or as large as 50%, depending on the topic).
Think back to the data presented in Activity 5, where there was a twofold difference between some farms and a sixfold difference between others. Which of these clinical differences would require a bigger sample size to demonstrate?
The twofold difference, because it is smaller.
Activity 7: Refining the sample size
Go back to the example and calculation you made in Activity 6. What happens if you:
- reduce only the confidence level to 90%?
- reduce only the power to 80%?
- increase only the proportion in the second province to 70%?
- make all three of the changes above?
Answer
- Changing only the confidence level to 90% reduces the total sample size to 3494.
- Changing only the power to 80% reduces the total sample size to 3210.
- Increasing only the proportion in the second province to 70% reduces the total sample size to 268.
- Making all three of the changes above reduces the total sample size to 166.
Were you surprised by how much the sample size changed when increasing the proportion in the second province? Try other changes to the parameter values and see what happens. Reflect on the guidance in the previous section about which parameters might be appropriate to change.
4.5 Additional considerations when calculating sample sizes
So far this module has introduced you to the concepts and methods for determining a suitable sample size for your research study or surveillance programme. However, there are many other considerations. You should always consult with an epidemiologist or statistician when planning to conduct a sample size calculation, as you may need to consider the following situations:
- When human populations are ‘clustered’ into households or hospital wards, or health facilities are clustered into districts or regions, it is necessary to take account of this clustering in the sample size calculation. There are a number of ways to achieve this, depending on the structure of the clustered population.
- Sometimes you might have multiple objectives for AMR surveillance, and it is important to ensure the overall sample size is sufficient for each of these. For example, you might want to compare differences in AMR between multiple regions, but also compare changes in AMR over time. You will need different sample size calculations for these two objectives. Make sure your calculated sample size meets the minimum required precision, confidence level and power of all your important objectives, not just the main or primary objective.
- Special methods (known as ‘exact’ methods) may need to be used to calculate sample size if the expected frequency of the multidrug-resistant organism or use of a particular antimicrobial being studied is very low; for example, if fewer than five isolates are expected. Where possible, avoid this situation by increasing your sample size.
- Various things can go wrong when collecting and processing samples. It might be impossible to reach the selected surveillance site due to flooding or bad weather. Specimens might be lost or accidentally destroyed during transport or in the laboratory. Combined, this is variously described as ‘dropout’, ‘loss to follow-up’ or ‘missing data’. As a general rule, increase your sample size by 5–10% above the calculated value to allow for dropouts.
5 Putting it all together: sampling for AMR studies and surveillance
This section puts many of the concepts you have learned in this module into the broader context in which they are applied: designing and conducting AMR studies and surveillance.
5.1 Types of surveillance and implications for sampling
In most cases, isolates from patients with infections are tested for resistant pathogens to guide clinical decision-making. That is, people who are unwell, particularly those admitted to hospital, have samples collected for bacterial identification and AST so that the most appropriate antimicrobial to which the infection is susceptible can be used in treatment. Generating surveillance data or monitoring the prevalence of AMR within the population is generally a secondary objective or an additional benefit of this testing. In general, this means that sampling for AMR happens within the context of
Sometimes, people who are healthy are asked to provide specimens (for example, skin or nasal swabs, or urine samples), to find out if resistant bacteria are present in healthy individuals. This is sometimes referred to as ‘asymptomatic carriage’ of resistant bacteria. This type of sampling happens in the context of
You can find out more about the difference between active and passive surveillance in Introducing AMR surveillance systems module.
Sampling in the context of passive surveillance
Usually, people sampled in the context of passive AMR surveillance are unwell. This has both advantages and disadvantages. Unwell people present to hospitals and other medical facilities and are therefore easily accessible. They are often tested to inform their treatment, and the cost of the testing may be covered by their health insurance or government funding. However, unwell people are not representative of the general population.
What are some reasons why unwell people do not represent the general population?
They are sick, whereas most people are healthy most of the time. Another reason is that they might be older.
When only sick hospitalised patients are selected for AMR surveillance, we cannot assume the results are externally valid for the whole human population in that region: hospitalised patients may be older or sicker, may have been exposed to more treatments, or may have easier access to hospitals, etc., than the general population. In contrast, younger or healthier people, or people with less access to hospitals, might get sick with a bacterial infection, but only seek care in their community. This means that the target population in these studeies should be defined as the hospitalised population, not the general population.
The importance of this depends on what you are studying. If you want to know more about resistance in bacteria causing bloodstream infections, you would only be interested in hospitalised patients because healthy people in the community don’t have bacteria in their bloodstream (if they did, they’d be unwell – and likely end up in hospital!) However, if you want to study asymptomatic carriage of methicillin-resistant Staphylococcus aureus (MRSA), or mild UTIs, looking at only hospitalised patients may not tell you very much about how many people in the community have certain types of resistant infections.
Passive surveillance also takes place in the community; for example, patients presenting to general practitioners with UTIs. There are advantages and disadvantages to hospital versus community sampling. Hospital patients are sampled more frequently than community-based patients, and they are a more accessible population in general. However, they also tend to differ more systematically from the general population than community-based patients. It is also difficult to determine if resistant pathogens found in hospital patients were acquired before they entered the hospital or in the hospital itself, especially if they have been in hospital for some time – though some resistant pathogens, such as MRSA, mainly occur in hospitalised patients. Community-based patients are sampled less frequently in most passive surveillance systems, but these patients, and the resistance profiles of the bacteria they carry, may be more representative of the general population and their pathogens. This is because of patients’ individual characteristics mentioned above (age, socio-economic status, etc.) and if resistant pathogens are isolated, it is likely patients were infected in the community rather than in a hospital or other healthcare setting.
Sampling in the context of active surveillance
As you have seen, sampling in the context of passive AMR surveillance means that there are likely to be challenges with bias (see the Fundamentals of data for AMR module). This is particularly because patients included in passive surveillance might not be representative of the source or target population, especially for bacterial diseases that could be found in people who are unwell in the community as well as people who are in hospital. (Remember that for severe bacterial infections such as bloodstream infections, almost everyone who gets sick will go to hospital, so there’s no bias caused by restricting surveillance to hospital settings!)
An alternative is to conduct active AMR surveillance; however, active surveillance programmes based on probability sampling methods as described above are resource-intensive and not always practical. So what can be done to generate reliable and comprehensive data on the frequency of resistant bacteria for common and sometimes self-limiting infections, such as UTIs? Researchers have proposed a cost-effective, practical way to determine the categorical level of resistant bacteria in a particular facility (such as a primary care facility) called
In the context of active AMR surveillance or research in healthy populations, where the topic of interest is carriage of a particular type of resistant bacteria, it can be difficult to identify people to sample because it is challenging to encourage those with no symptoms to undergo testing. Moreover, sampling people purely for surveillance purposes in a representative way is expensive and resource-intensive, and has ethical implications that need considering. This is one reason why environmental sampling strategies are being developed, such as testing sewage (wastewater) for resistant pathogens.
Alternatively, research studies actively seek volunteers to participate in research. This can be a useful way to sample people outside of healthcare settings; however, research participants also differ systematically from the general population. For example, many research studies exclude population groups such as children or pregnant women from participating in research, to protect them from any risk of harms from doing so. (See the Legal and ethical considerations in AMR data module if you are interested in ethical aspects of AMR.) However, this exclusion also means data may not be available for these groups.
5.2 Relating sampling units to isolates
So far, we have been talking about sampling and sample size calculations without specifying whether we mean physical specimens (such as faecal or urine samples) or a
The WHO’s Global AMR Surveillance System (GLASS) sets four priority specimen types and eight priority pathogens. The four priority specimen types are:
- blood
- urine
- stool
- genital swabs.
The eight priority pathogens are:
- E. coli
- Klebsiella pneumoniae
- Acinetobacter spp.
- S. aureus
- Streptococcus pneumoniae
- Salmonella spp.
- Shigella spp.
- Neisseria gonorrhoeae.
GLASS outlines which pathogens should be isolated from which specimens. Each hospital, region or country might have additional priority bacterial species to test for AMR.
In general, sample size calculations in AMR studies are based on the number of bacterial isolates, not the number of specimens or number of individuals (noting that there is usually one specimen per individual). Recall in Activity 3 that only 840 positive cultures were obtained from 3380 patients.
The type of bacteria being sampled affects the proportion of samples in which isolates can be expected to be identified, and therefore the final sample size calculation for the number of specimens (i.e. number of people) from which isolates are obtained. When making use of existing data in passive surveillance systems, the target population might be defined as ‘all patients presenting with gastroenteritis in hospitals’. In this case, it is likely that E. coli spp will be isolated from 100% of specimens (and therefore 100% of sampling units), because we all have E. coli spp. in our gut. Therefore, if our study is about AMR in E. coli, one specimen represents one isolate for the purpose of sample size calculations.
In other cases, not all specimens will contain disease-causing bacteria of interest. In this case, you would need to adjust the sample size based on the proportion of individuals expected to have the target pathogen isolated from their specimen sample. We’ll review an example in Activity 8.
Activity 8: Sampling in action
Asymptomatic nasal carriage of S. aureus is common; nasal carriage of methicillin-resistant strains is rarer, but is a risk factor for developing MRSA infections. Imagine you want to estimate the prevalence of MRSA among people with nasal carriage of S. aureus. Can you work out the total number of individuals to sample, if the sample size calculation suggests that 246 S. aureus isolates are needed for a precise estimate of MRSA prevalence, and only 20% of individuals in the source population are expected to have nasal carriage of S. aureus?
Discussion
To calculate the total number of individuals to sample, divide the number of isolates by the proportion of samples that contain the required bacteria. In this case, we divide 246 by 0.2 (which is the same as 20%), giving us a total sample size of 1230 specimens. In practice, there is a range of other adjustments that would need to be made to this sample size calculation, such as adjusting for clustering of individuals in the same wards, hospitals or other types of health facilities.
When you plan this kind of sampling, it is always worth asking whether a sample size calculation is needed. In passive surveillance, samples submitted to a laboratory for AST to inform clinical decision-making are utilised. In some cases, these existing datasets can be analysed without first specifying a sample size, because they represent the maximum available data from all patients in the source population.
However, a sample size calculation is usually required even if the data already exist. For example, a sample comprising patient records from a single healthcare facility might be too small for the desired power. Researchers and surveillance professionals should be aware of this before beginning analysis. Additionally, as each hospital or healthcare facility might have a separate ethical review process for accessing patient records, it is often necessary to justify how many samples and hospitals are required for a research study to meet its objectives.
5.3 Steps involved in sampling for AMR
You should consider the following steps when sampling people or healthcare facilities for AMR surveillance:
- Decide on your target population: What is the most relevant population to which you want to generalise the findings of your study or surveillance programme?
- Decide on the source population: In most cases, this will be individuals attending healthcare facilities such as hospitals or primary healthcare centres, but it could also be healthy individuals, especially for surveillance for carriage rather than disease.
- Outline a sampling frame: This might be a list of all hospitals or healthcare facilities in the target population. Remember that it is ideal to have at least 80% of the total target population listed in the sampling frame, although this can be difficult to achieve.
- Determine a sampling strategy, including how to select sampling units: Consider using probability sampling methods.
- Calculate the required sample size: This may require more than one calculation (such as the number of hospitals and then number of patients per hospital), and may require adjustment in light of non-statistical determinants of sample size. Be sure to consider whether you need to adjust the number of people to sample if the target bacterial species are not expected to be isolated from all samples.
Activity 9: Planning your own sampling
Think of a target population of interest to you in your role, or in your country more generally. If you can’t think of an example, consider the following population: neonates (infants less than four weeks old) with sepsis (bacterial infections of the blood). Think about an important research or surveillance question (such as the proportion of neonatal sepsis cases caused by a resistant pathogen) and use the space below to reflect on the steps for planning sampling:
- What are the possible source populations? What are the options in healthcare facilities and in community settings?
- Identify your target bacterial species. For your example, is it of more interest to focus on patients with clinical disease, or asymptomatic carriage of disease-causing bacteria?
- Identify a possible sampling frame, and the source of information for this sampling frame.
- What type of sampling method would you use? Are there advantages to using multistage sampling compared to simple random sampling?
- What considerations might you need to take into account when preparing a sample size calculation? Do you expect the target bacteria to be present in all the samples collected? Do you need to take dropout or clustering into account?
Discussion
How did you get on with this activity?
If you used the example of neonatal sepsis, you may have considered the following steps:
- In countries with good healthcare access, it might be assumed that almost all neonates with sepsis will present to a hospital and be admitted to a neonatal intensive care unit (NICU), in which case NICUs might be a good source. In countries with areas of limited healthcare access, many cases of neonatal sepsis might occur in the community, and never present to a health facility. Depending on your context, you might want to consider patients attended to by community maternal and infant health workers as well as patients presenting to health facilities.
- A range of bacterial species cause neonatal sepsis, especially Gram-negative pathogens such as Klebsiella pneumoniae, Pseudomonas aeruginosa or Acinetobacter spp. For this study, all bacteria found to be the cause of sepsis in neonates might be included.
- A possible sampling frame might be all neonates with fever and other typical symptoms of sepsis, attended to by a community health worker and/or a list of inpatients at a NICU or other health facility over the study period.
- Neonatal sepsis is relatively rare: around 2200 cases per 100,000 live births globally (Fleischmann-Struzek et al., 2018). If your target population includes only 10,000 births, you therefore might aim to include every neonatal sepsis case that arises in the source population; that is, around 220 cases. If you have data for the entire country, you might randomly sample medical facilities or communities, and then select all cases that arise within those primary sampling units (clustered sampling).
- There is a number of considerations related to the sample size. Your considerations might relate to the expectation of the frequency of the target bacteria being isolated. In neonatal sepsis, clearly some kind of bacteria will be identified in all cases, though there are different bacteria responsible, so not all cases may have the target pathogen if you are interested in only one type of bacteria that causes sepsis. You might also consider the anticipated drop-out rate. If you are conducting this analysis as part of a research study, the caregivers of some neonates might not wish to participate in a study, so you might need to be prepared to invite more caregivers to enrol their infants than the sample size requirement indicates.
6 End-of-module quiz
Well done – you have reached the end of this module and can now do the quiz to test your learning.
This quiz is an opportunity for you to reflect on what you have learned rather than a test, and you can revisit it as many times as you like.
Open the quiz in a new tab or window by holding down ‘Ctrl’ (or ‘Cmd’ on a Mac) when you click on the link.
7 Summary
In this module you have learned about different approaches to sampling for AMR studies and surveillance in people. You have learned about important parameters and best practice methods for sampling people, and you have also learned that many AMR studies and surveillance programmes use less-than-ideal sampling methods.
You should now be able to:
- describe the purpose of sampling individuals for AMR surveillance
- explain what factors need to be considered when choosing which individuals to sample for AMR surveillance
- recognise the lists of priority pathogens suggested for sampling in individuals
- list the steps involved in sampling individuals for AMR surveillance
- explain the common problems associated with identifying sampling frames and how they can be addressed.
Now that you have completed this module, consider the following questions:
- What is the single most important lesson that you have taken away from this module?
- How relevant is it to your work?
- Can you suggest ways in which this new knowledge can benefit your practice?
When you have reflected on these, go to your reflective blog and note down your thoughts.
Activity 10: Reflecting on your progress
Do you remember at the beginning of this module you were asked to take a moment to think about these learning outcomes and how confident you felt about your knowledge and skills in these areas?
Now that you have completed this module, take some time to reflect on your progress and use the interactive tool to rate your confidence in these areas using the following scale:
- 5 Very confident
- 4 Confident
- 3 Neither confident nor not confident
- 2 Not very confident
- 1 Not at all confident
Try to use the full range of ratings shown above to rate yourself:
When you have reflected on your answers and your progress on this module, go to your reflective blog and note down your thoughts.
8 Your experience of this module
Now that you have completed this module, take a few moments to reflect on your experience of working through it. Please complete a survey to tell us about your reflections. Your responses will allow us to gauge how useful you have found this module and how effectively you have engaged with the content. We will also use your feedback on this pathway to better inform the design of future online experiences for our learners.
Many thanks for your help.
References
Acknowledgements
This free course was collaboratively written by Melanie Bannister-Tyrrell, Emma Zalcman and Clare Sansom, and reviewed by Siddharth Mookerjee, Claire Gordon, Natalie Moyen and Hilary MacQueen.
Except for third party materials and otherwise stated (see terms and conditions), this content is made available under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 Licence.
The material acknowledged below is Proprietary and used under licence (not subject to Creative Commons Licence). Grateful acknowledgement is made to the following sources for permission to reproduce material in this free course:
Images
Module image: AndreasReh/Getty Images.
Figures 1 and 2: Ausvet Pty Ltd.
Figure 3: Adapted from Mills, H.L. et al. (2018) ‘Evaluation of metrics for benchmarking antimicrobial use in the UK dairy industry’, Veterinary Record, 182(13), p. 379. doi: 10.1136/vr.104701. This file is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) licence, https://creativecommons.org/ licenses/ by/ 4.0/.
Text
Activity 3: Sugianli, A. et al. (2017) ‘Antimicrobial resistance in uropathogens and appropriateness of empirical treatment: a population-based surveillance study in Indonesia’, Journal of Antimicrobial Chemotherapy, 72(5), pp. 1469–77, https://doi.org/ 10.1093/ jac/ dkw578. This file is licensed under a Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) licence, https://creativecommons.org/ licenses/ by/ 4.0/.
Section 5.1: Ginting, F. et al. (2019) 'Rethinking Antimicrobial Resistance Surveillance: A Role for Lot Quality Assurance Sampling', American Journal of Epidemiology, Vol. 188, Issue. 4, April 2019, pp. 734–742, https://doi.org/10.1093/aje/kwy276 . An Open Access article distributed under the terms of the Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) license, https://creativecommons.org/licenses/by-nc/4.0/
Every effort has been made to contact copyright owners. If any have been inadvertently overlooked, the publishers will be pleased to make the necessary arrangements at the first opportunity.