
5 Large language models
Anyone wanting to use GenAI tools for legal information is likely to use tools which produce text answers to the text queries put into it. These are called large language models (LLMs): GenAI systems that are specifically focused on understanding and generating natural language tasks. They are capable of self-supervised learning and are trained on vast quantities of text taken from the world wide web.
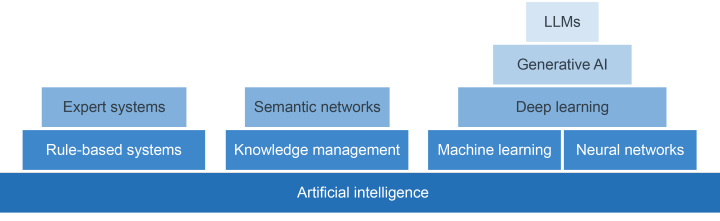
The most familiar LLMs would be the conversational versions – such as ChatGPT, Gemini, Claude, Llama, DeepSeek and others. In September 2024, Meta’s Llama 3.1 was considered to be the largest LLM with 405 billion parameters, trained on over 15 trillion ‘tokens’ (crudely, tokens are words or parts of words captured from publicly available sources).
 Using prompts with an LLM
Using prompts with an LLM
Open an LLM – at the time of writing, ChatGPT, Gemini, Claude and Llama offer free versions. Copy and paste the text below into the search bar:
‘Explain how individuals in the UK can obtain free legal advice and assistance.’
(This is called a prompt, and you will find out more about how to use them in the second course in this series: Skills and strategies for using GenAI.)
If you cannot use an LLM, you can read the response to this prompt which ChatGPT4o generated – Prompt to ChatGPT 4o on 24 February 2025.
What did you think about the result? Did anything surprise or concern you?
Discussion
Looking at the response from ChatGPT=4o, it is surprising how well structured the answer was. It was easy to read and understand and sounded very persuasive.
However, there were some errors in the response – for example, legal aid is only available in limited family, housing, immigration and welfare benefits appeals cases. The Civil Legal Advice government service will only advise on certain limited types of cases.
Finally, local councils do not provide free legal advice: they may refer you to the local law centre, but many of these have closed due to a lack of funding. You will find out more about some of these concerns later on in this course.
The competency shown by large language models came as a surprise. With language models, up to a certain point, the model's performance improved steadily as it increased in size. But after this point there was a sudden leap in abilities which couldn't be predicted by just considering smaller versions of the system. The LLM’s ability to mimic human language generation and apparent general intelligence was a result of the scaling-up of the systems.
The scaling up of the tools was possible because all of the LLMs referred to in this section are pre-trained models: they have already been trained on large amounts of training data. While it is quicker and more efficient for users to choose pre-trained models, there are a number of disadvantages. For example, the tool may not work efficiently for a very specific task.
In these circumstances, the user can fine-tune the tool by giving it additional datasets specific to the proposed use. Whilst this costs more than simply using a pre-trained model, it is much more efficient than training a GenAI tool from scratch.
So how do these tools decide what information to give in their responses? We explore this in the next section.
4 The development of Generative AI
