

2.1.2 Variables
A
Activity 3: Common variables for characterising data units
In your workplace, what data units are most often used and what are some of the common variables that might be relevant for characterising these units?
Some variables can be observed or recorded directly – for example, the body temperature of a person or animal can be observed by reading the result on the thermometer, providing it is working and used correctly. Other variables are defined by applying rules or calculations to directly observed variables. For example, the variable ‘fever’ might be based on a binary classification of body temperature, with any patients recording a body temperature higher than 37.5°C classified as having a fever, while those with a body temperature of 37.5°C or less classified as ‘no fever’. Similarly, ‘age in years’ can be recorded directly or calculated from the documented date of birth.
Variables can be further classified into
Consider once more the example of body temperature. Imagine that you measure the body temperature of five patients using a standard thermometer, with the results shown in Table 2.
| Patient number | Body temperature |
|---|---|
| 1 | 36.6°C |
| 2 | 41.2°C |
| 3 | 37.6°C |
| 4 | 37.4°C |
| 5 | 20.5°C |
Now imagine that you have data for the same patients, but this time the data is represented using the variable ‘Fever’, which has two categories, ‘Yes’ and ‘No’. Their body temperatures are shown again in Table 3. A cut-off value of 37.5°C or above is used to determine whether the patient has a fever.
| Patient number | Body temperature | Fever |
|---|---|---|
| 1 | 36.6°C | No |
| 2 | 41.2°C | Yes |
| 3 | 37.6°C | Yes |
| 4 | 37.4°C | No |
| 5 | 20.5°C | No |
Activity 4: Different types of information implied by ‘body temperature’ and ‘fever’ variables
What do you notice about these two variables, ‘body temperature’ and ‘fever’? What different types of information are implied by each variable?
Discussion
‘Body temperature’ is an example of a numeric (quantitative) variable, whereas ‘fever’ is an example of a categorical (qualitative) variable. In general, there is more information available when the data are presented as numeric variables. In this example, we can see that patient 2 has a very high body temperature, which might indicate a life-threatening infection. We can also see that patients 3 and 4 have a mildly elevated temperature and their values are very similar (only 0.2°C difference). However, when the cut-off is applied, only patient 3 is classified as having ‘fever’. Finally, we observe that the body temperature of patient 5 is implausibly low, and is therefore likely to be an error (the thermometer might be broken or the user might not have read it properly – or possibly, the patient might be dead!) We would not detect this problem if we only had access to the variable ‘fever’, as this patient is simply categorised as having no fever. In fact, we would normally remove this observation from our analysis as it is a clear error.
Despite containing less information overall, categorical variables are still very useful. For example, it is both simpler and more clinically meaningful to describe the proportion of hospitalised patients with blood infections who have fever, than describing their average body temperature. Using categorical variables also means that comparisons can be made between groups, for example comparing outcomes for patients classified as having a fever versus patients with ‘no fever’. There is more detail on how to describe and summarise different types of data in the Processing and analysing AMR data module.
By now you can probably infer some of the key differences between numeric and categorical variables.
- data are represented as counts or measurements
- data are represented using numeric values as integers (1, 2, 3), fractions (½, ¼) decimals (37.7, 39.134) or percentages (20%, 50%)
- include age, height, blood pressure and minimum inhibitory concentration.
- data are represented as belonging to a particular group (a ‘category’)
- can be represented by a name, a string of alphanumeric characters, or numeric values
- include sex/gender, occupation and antimicrobial class.
In addition to classification as ‘numeric’ or ‘categorical’, variables are further defined by what they measure (see Figure 1).
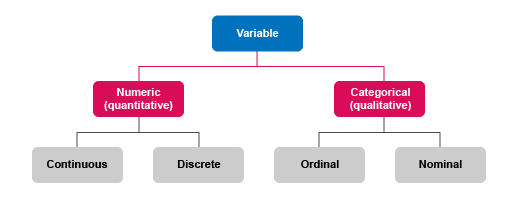
Numeric variables can be either continuous or discrete.
Continuous variables:
- represent measurements that can take any value within a range
- can be recorded using integers, fractions, percentages or decimals
- examples include milligrams of antimicrobial ingredient per kilo of bodyweight.
Discrete variables:
- represent counts of individual items or values
- are always recorded using integers (whole numbers)
- examples include the number of animals in a herd, number of different antimicrobials to which resistance is identified.
Categorical variables can be either nominal or ordinal.
Nominal variables:
- are classified into two or more categories that are mutually exclusive
- have no intrinsic order or ranking, or distance between the values
- when there are only two categories, this is known as a ‘dichotomous’ or ‘binary’ variable
- examples include antimicrobial class, pregnancy status and all yes/no questions.
Ordinal variables:
- comprise three or more categories that are ‘ordered’ or ‘ranked’, so that one value is ‘larger’ or ‘smaller’ than another value
- the distance, or gap, between values is not necessarily equal
- examples include body mass index (BMI) category (underweight, normal weight, overweight, obese) and resistance category (susceptible, intermediate, resistant).
The reason that variable classifications matter is that each one affects how data can be analysed, interpreted and used. You’ll learn more about this in the Processing and analysing data module. The key takeaway for this module, however, is to recognise that variable classifications are partly determined by the nature of the data unit that is being measured (for example, you can’t have half a person, so counts of people or animals are always discrete), and partly determined by how data are processed (such as when categorical variables are generated from continuous variables).
Activity 5: Classifying age variables
a.
Ordinal variable
b.
Categorical variable
c.
Continuous variable
d.
Discrete variable
The correct answer is a.
a.
Ordinal variable
b.
Categorical variable
c.
Continuous variable
d.
Discrete variable
The correct answer is c.
a.
Ordinal variable
b.
Categorical variable
c.
Continuous variable
d.
Discrete variable
The correct answer is a.
2.1.1 What are data?
