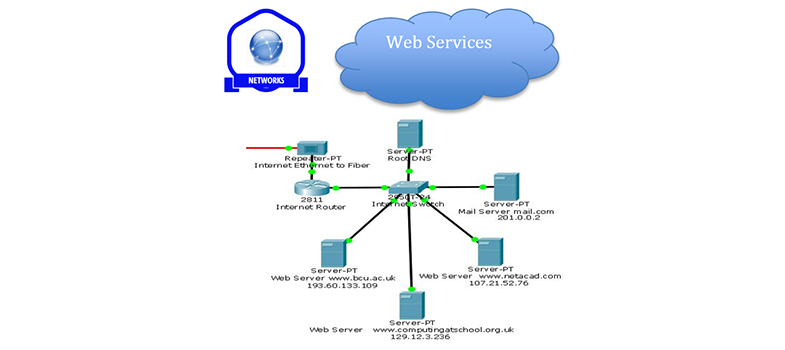
3 The WWW and web crawlers
- The WWW consist of an extremely large collection of web pages (more than 4 billion in 2017) stored at more than a billion websites. You can view the current numbers here [Tip: hold Ctrl and click a link to open it in a new tab. (Hide tip)] .
- Because of the speed at which websites are being added to the WWW, finding sites you are interested in can be quite a challenge. You have probably used a search engine to find web pages, but how do they know about all the new websites continually being added to the WWW?
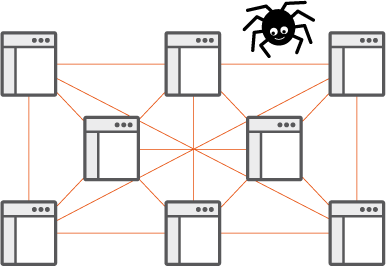
Figure 4
- Search engines use special computer programs called web crawlers to automatically learn about new content when it is added to the WWW.
- Web crawlers browse the WWW in a methodical manner, copying web page content, including Uniform Resource Locators (URLs) linking to other web pages and sending it to the search engine. This information is then processed by the search engine, which stores key words and information in such a way it can be accurately searched by web users. This processing of web page information collected by web crawlers is called indexing.
- The URLs used by web crawlers provide a unique identity for each web page, and indicate where it is stored:

Figure 5
- When a web crawler is started, it is provided with a list of URLs (called seeds), which it then visits. It collects all the URLs of hyperlinks it finds at these sites. These are then added to the list of sites for the web crawler to visit, providing an expanding set of pages to search and copy:
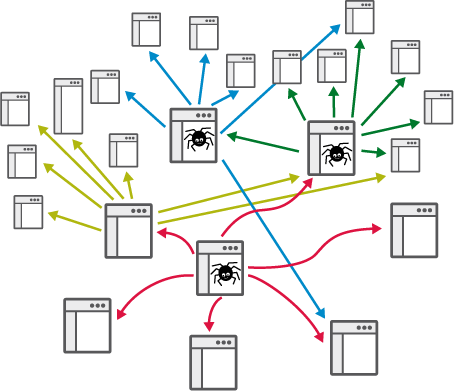
Figure 6
- Due to the size of the WWW, and the rate at which it grows, web crawlers are not able to search all the pages in existence while also checking known pages for updates. Even large search engines like Google have not indexed the entire WWW.
Back to previous pagePrevious
2 The WWW as a service