

1.1 Scholarly communication over the centuries
Standing on shoulders
In 1665 the Royal Society of London launched Philosophical Transactions of the Royal Society, the first open, peer-reviewed journal still in publication today. This familiar mode of scholarly communication was created to further the Royal Society’s mission to promote knowledge. Isaac Newton, who became the Society’s president in 1703, said ‘If I have seen further it is by standing on the shoulders of Giants’, which today is a slogan for intellectual progress building on the sharing of previous work.
Activity 1 Browsing the Philosophical Transactions archive
The founding editor of Philosophical Transactions, Henry Oldbenburg, published ‘An introduction to this tract’. Follow this link to a digitised copy of Vol. 1, Issue 1, pp. 1–2 of the Philosophical Transactions [Tip: hold Ctrl and click a link to open it in a new tab. (Hide tip)] (dated 6 March 1665) on the Royal Society Publishing website. Click on ‘View PDF’ to read it. Find and read the text beginning ‘To the end, that such Productions being clearly and truly communicated...’ on p. 2.
You can also look at some of the high quality scans from the archive.
Now look at a recent Philosophical Transactions paper – for example: The evolution of the web and implications for eResearch. What are the differences between the journal culture and practice of 1665 and today?
Analysing authorship over time
Scholarly practice has changed since 1665, yet the principles and presentation of Philosophical Transactions and its successors have remained similar.
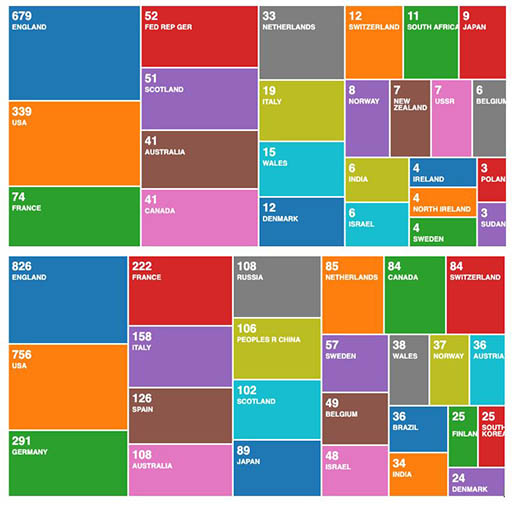
This publishing ecosystem is itself something we can analyse, and the tools which help us discover content can also be used to analyse the publishing process at scale. As an example of these tools, here’s a visualisation of the number of Philosophical Transactions articles by country of author during the period 1973–83 and 2010–2020, produced online using Web of Science. The trends are clear – though we need to know which publications are included in the corpus we are searching (i.e. absence of evidence is not evidence of absence).
Knowledge infrastructure
Knowledge Infrastructures are defined by Paul N. Edwards et al. as ‘robust networks of people, artifacts, and institutions that generate, share, and maintain specific knowledge about the human and natural worlds’, and include individuals, organisations, routines, shared norms and practices (2013, p. 5). It’s useful to adopt this inclusive definition, for example, it would include this course, or an archive or a library, and includes people: knowledge infrastructure is fundamentally socio-technical.
Knowledge Infrastructure evolves as researchers embrace digital techniques to explore established research fields through new ways, with digitised and born-digital collections. Pervasive adoption of technology, coupled with new social processes, has created a complex new space for scholarship – citizens both generate and analyse data as they interact both physically and digitally. This rapid increase in infrastructure is in tension with its established forms, more tensions emerge as computational power, automation, and adoption of Artificial Intelligence grow.
(Thanks to Pip Wilcox, The National Archives, for co-authoring the text in this section.)
Social editions
The web was invented at CERN (the European Organization for Nuclear Research) to enhance science communication. It now is a fundamental part of our scholarly knowledge infrastructure – and enables the creation of new infrastructures. Wikipedia is a powerful example. It’s the most widely used general reference work on the web, growing since 2001 to hold over 6 million articles in the English language (for comparison, Encyclopaedia Britannica has less than a million).
Wikipedia is an example of what Ray Siemens calls a social edition, capitalising on engaged knowledge communities inside and outside the academy (Siemens, 2012, p. 452).
Activity 2 Wikipedia in action
Wikipedia is an open platform keeping track of the edit history of all its pages, meaning we can examine this ‘social machine’ in operation over time.
Find a page on a familiar topic and select ‘View history’. In this interface you can select two past versions of the page and compare them to explore which contributions have been ‘reverted’. What are the common reasons for reversion?
Citizen Science
In 2007, astrophysics researchers had too many images of galaxies to classify by hand, so they put them on the web and turned to a larger volunteer community to help. The result is the Zooniverse citizen research platform which today reports over 500 million classifications by 2 million volunteers.
The Zooniverse platform now delivers projects across multiple domains including Humanities – a significant Knowledge Infrastructure capability. Today anyone can create a citizen research project using the Zooniverse Project Builder with tools including annotation (tagging, drawing) and transcription.
The original Galaxy Zoo project is still on Zooniverse, and with an option to use an enhanced version: the huge volunteer workforce cannot keep pace with the images, so the platform has now developed ‘machine learning’ alongside volunteer effort.