

8 Representing images in binary
On a screen, images are generated by dividing the display into a large number of tiny units called pixels (from ‘picture elements’). Each pixel can, in general, be displayed in a number of different colours and levels of light intensities or brightness. The greater the number of pixels used for a given size of display, the more detail can be displayed and the higher the quality of the image.
Now you’ll consider an artificially small-scale example: a display using eight rows of sixteen pixels. In Figure 2 you can see how this system could display a ‘triangle’.
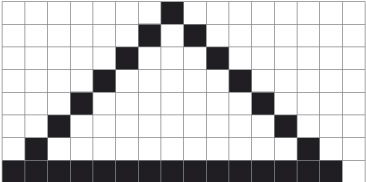
Activity 5
What do you notice about the representation of the three sides of the ‘triangle’?
Discussion
The horizontal side is a perfect straight line, since all the pixels are lined up along the row. The other sides have a stepped appearance, and only approximate a straight line. You may have noticed this effect on old mobile phone displays, which often used only a small number of pixels compared with, say, a computer display or the screen on a contemporary smartphone.
Next time you use your computer, look at a photograph and ‘zoom in’ as far as you can (usually an option under the View menu) to examine it in detail. The number of pixels in the ‘zoomed in’ section hasn’t changed, but each pixel has expanded in the display so that it is possible to see each one as a discrete square. From normal viewing distances, each pixel merges with its neighbour so that we see a smooth image.
In other words, we have taken the smooth images we see around us, and broken them into tiny units that can be represented in binary to a processor, and when viewed appropriately, can still look like a smooth image to us.
For the simple black and white triangle, we can represent the state of each pixel with a bit, setting it to 0 for white and 1 for black. For more colours, we will need to use more bits at each pixel. If we use two bits at each pixel we can have four colours (remember 2 x 2 = 22 = 4) so that we could use 00 for white and 11 for black, and 01 for red and 10 for blue. As we use more bits at each pixel we can add more information and show a greater variety of colours as well as other aspects of the picture such as how bright the pixel is.
Adding more detail to each pixel needs more bits to record that detail. Consider a screen that has a resolution of 1920 by 1080 pixels. That means there are 2 073 600 pixels on the screen when you look at it. If one byte is used to record the colour and so on of each pixel (remember one byte is eight bits), that means 16 588 800 bits of data are needed to describe the screen.
In some professional video applications, three bytes (24 bits) are used to store the data to be displayed at each pixel. That means 49 766 400 bits of data are needed to display one image measuring 1920 x 1080 pixels.
You may have come across the term 4K, which is used to describe an increasingly popular television and cinematography display resolution. 4K UHD is the dominant standard (there are several 4K standards!) and is four times the size of my monitor. In other words, the display is 3840 x 2160 pixels, or 8 294 400 pixels. Consider the number of bits needed to display an image of that size if each pixel has one byte to record its colour and additional detail such as brightness.
As file sizes increase so it is harder to process them (they simple take longer to process because there are more individual data elements to work on and more memory is needed to store this data while it is being processed). It becomes harder to use large files in other ways too. Some are obvious: consider the time taken to download an image or to stream a video over the internet; other perhaps less so: consider the size of your backup files.
There has been much research into making image files easier to handle producing a variety of standards depending on the application, such as jpeg (defined by the Joint Photographic Experts Group) which is particularly suited to photographs, gif (Graphics Interchange Format) which is particularly suited to simple graphics, and png (Portable Network Graphics) which is particularly suited to online viewing.