

1.5 Design
Database design starts with a conceptual data model and produces a specification of a logical schema; this will usually determine the specific type of database system (network, relational, object-oriented) that is required, but not the detailed implementation of that design (which will depend on the operating environment for the database such as the specific DBMS available). The relational representation is still independent of any specific DBMS; it is another conceptual data model.
Our approach here is to use a relational database environment. We can use a relational representation of the conceptual data model as input to the design process. The output of the design stage is a detailed relational specification, the logical schema, of all the tables and constraints needed to satisfy the description of the data in the conceptual data model. It is during the design activity that choices are made as to which tables are most appropriate for representing the data in a database, such as for the sample hotel example in section 1. These choices must take into account various design criteria including, for example, flexibility for change, control of duplication and how best to represent the constraints. It is the tables defined by the logical schema that determine what data are stored and how they may be manipulated in the database.
Database designers familiar with relational databases and SQL might be tempted to go directly to implementation after they have produced a conceptual data model. However, such a direct transformation of the relational representation to SQL tables does not necessarily result in a database that has all the desirable properties: completeness, integrity, flexibility, efficiency and usability. A good conceptual data model is an essential first step towards a database with these properties, but that does not mean that the direct transformation to SQL tables automatically produces a good database. This first step (sometimes called a first-cut design) will accurately represent the tables and constraints needed to satisfy the conceptual data model description, and so satisfies the completeness and integrity requirements, but it may be inflexible or offer poor usability. The first-cut design is then flexed to improve the quality of the database design. Flexing is a term that is intended to capture the simultaneous ideas of bending something for a different purpose and weakening aspects of it as it is bent.
Using relational theory for a formal design
There will be occasions when it is necessary to prove formally that a database satisfies given requirements. Using relational theory can allow a relational representation of a conceptual data model to be analysed rigorously. This stage, which is usually omitted in all but the most exacting development environments (such as safety-critical systems), involves using the formal properties of the relational theory to mathematically prove properties of the conceptual data model that would then be realised in the database design.
Figure 6 summarises the iterative (repeated) steps involved in database design, based on the overview given. Its main purpose is to distinguish the general issue of what tables should be used from the detailed definition of the constituent parts of each table – these tables are considered one at a time, although they are not independent of each other. Each iteration that involves a revision of the tables would lead to a new design; collectively they are usually referred to as second-cut designs, even if the process iterates for more than a single loop.
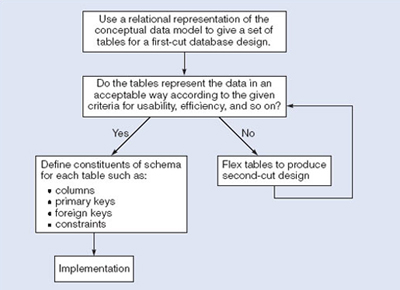
Before we turn to consider implementation, you should note three general points that form the basis of our design approach.
First, for a given conceptual data model it is not necessary that all the user requirements it represents have to be satisfied by a single database. There can be various reasons for the development of more than one database, such as the need for independent operation in different locations or departmental control over ‘their’ data. However, if the collection of databases contains duplicated data and users need to access data in more than one database, then there are of course further issues related to data replication and distribution.
second, remember that one of the assumptions about our database development is that we can separate the development of a database from the development of user processes that make use of it. This is based on the expectation that, once a database has been implemented, all data required by currently identified user processes have been defined and can be accessed; but we also require flexibility to allow us to meet future requirements changes. In developing a database for some applications it may be possible to predict the common requests that will be presented to the database and so we can optimise our design for the most common requests.
Third, at a detailed level, many aspects of database design and implementation depend on the particular DBMS being used. If the choice of DBMS is fixed or made prior to the design task, that choice can be used to determine design criteria rather than waiting until implementation. That is, it is possible to incorporate design decisions for a specific DBMS rather than produce a generic design and then tailor it to the DBMS during implementation.
It is not uncommon to find that a single design cannot simultaneously satisfy all the properties of a good database. So it is important that the designer has prioritised these properties (usually using information from the requirements specification), for example, to decide if integrity is more important than efficiency and whether usability is more important than flexibility in a given development.
At the end of our design stage the logical schema will be specified by SQL data definition language (DDL) statements, which describe the database that needs to be implemented to meet the user requirements.