2.4 Rapid serial visual presentation
It has been known for a long time that backward masking can act in one of two ways: integration and interruption (Turvey, 1973). When the SOA between target and mask is very short, integration occurs; that is, the two items are perceived as one, with the result that the target is difficult to report, just as when one word is written over another. Of more interest is masking by interruption, which is the type we have been considering in the previous section. It occurs at longer SOAs, and interruption masking will be experienced even if the target is presented to one eye and the mask to the other. This dichoptic (two-eyed) interaction must take place after information from the two eyes has been combined in the brain; it could not occur at earlier stages. In contrast, integration masking does not occur dichoptically when target and mask are presented to separate eyes, so presumably occurs quite early in analysis, perhaps even on the retina. On this basis, Turvey (1973) described integration as peripheral masking, and interruption as central masking, meaning that it occurred at a level where more complex information extraction was taking place.
Another early researcher in the field (Kolers, 1968) described the effect of a central (interruption) mask by analogy with the ‘processing’ of a customer in a shop. If the customer (equivalent to the target) comes into the shop alone, then s/he can be fully processed, even to the extent of discussing the weather and asking about family and holidays. However, if a second customer (i.e. a mask) follows the first, then the shopkeeper has to cease the pleasantries, and never learns about the personal information. The analogy was never taken further, and of course it is unwise to push an analogy too far. Nevertheless, one is tempted to point out that the second customer is still kept waiting for a while. Where does that thought take us? It became possible to investigate the fate of following stimuli, in fact whole queues of stimuli, with the development of a procedure popularised by Broadbent (Broadbent and Broadbent, 1987), who, like Treisman, had moved on from auditory research. The procedure was termed Rapid Serial Visual Presentation, in part, one suspects, because that provided the familiar abbreviation RSVP; participants were indeed asked to repondez s'il vous plait with reports of what they had seen.
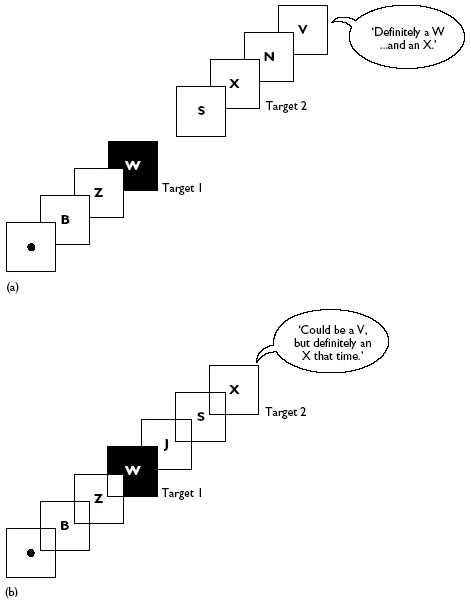
Unlike the traditional two-stimulus, target/mask pairing, Rapid Serial Visual Presentation (RSVP) displayed a series of stimuli in rapid succession, so each served as a backward mask for the preceding item. SOAs were such that a few items could be reported, but with difficulty. Typical timings would display each item for 100 ms, with a 20 ms gap between them; the sequence might contain as many as 20 items. Under these conditions stimuli are difficult to identify, and participants are certainly unable to list all 20; they are usually asked to look out for just two. In one variation, every item except one is a single black letter. The odd item is a white letter, and this is the first target; the participant has to say at the end of the sequence what the white letter had been. One or more items later in the sequence (i.e. after the white target), one of the remaining black letters may be an ‘X’. As well as naming the white letter, the participant has to say whether or not X was present in the list. These two targets (white letter and black X) are commonly designated as T1 and T2. Notice that the participant has two slightly different tasks: for T1 (which will certainly be shown) an unknown letter has to be identified, whereas for T2 the task is simply to say whether a previously designated letter was presented. These details, together with a graph of typical results, are shown in Figure 3.
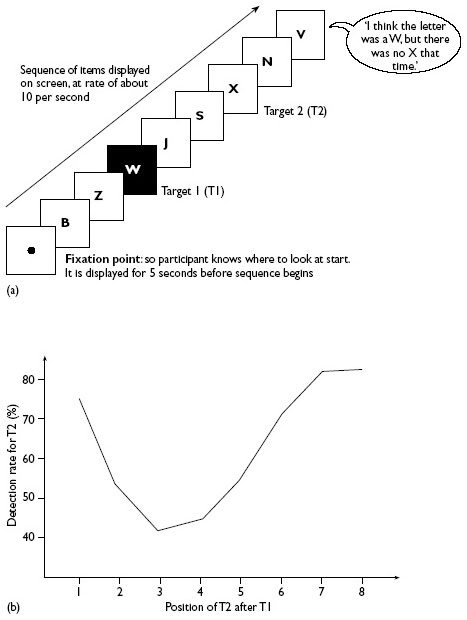
As can be seen from the graph in Figure 3b, T2 (the X) might be spotted if it is the item immediately following T1, but thereafter it is less likely that it will be detected unless five or six items separate the two. What happens when it is not detected? As you may be coming to expect, the fact that participants do not report T2 does not mean that they have not carried out any semantic analysis upon it. Vogel et al. (1998) conducted an RSVP experiment that used words, rather than single letters. Additionally, before a sequence of stimuli was presented, a clear ‘context’ word was displayed, for a comfortable 1 second. For example, the context word might be shoe, then the item at T2 could be foot. However, on some presentations T2 was not in context; for example, rope. While participants were attempting to report these items, they were also being monitored using EEG (electro-encephalography). The pattern of electrical activity measured via scalp electrodes is known to produce a characteristic ‘signature’, when what might be called a mismatch is encountered. For example, if a participant reads the sentence He went to the café and asked for a cup of tin, the signature appears when tin is reached. The Vogel et al. (1998) participants produced just such an effect with sequences such as shoe – rope, even when they were unable to report seeing rope. This sounds rather like some of the material discussed earlier, where backward masking prevented conscious awareness of material that had clearly been detected. However, the target in the RSVP situation appears to be affected by something that happened earlier (i.e. T1), rather than by a following mask. The difference needs exploring and explaining.
Presumably something is happening as a result of processing the first target (T1), which temporarily makes awareness of the second (T2) very difficult. Measurements show that for about 500 to 700 ms following T1, detection of T2 is lower than usual. It is as if the system requires time to become prepared to process something fresh, a gap that is sometimes known as a refractory period, but that in this context is more often called the attentional blink, abbreviated to AB. While the system is ‘blinking’ it is unable to attend to new information.
Time turns out not to be the only factor in observing an AB effect (‘AB effect’ will be used as a shorthand way of referring to the difficulty of reporting T2). Raymond et al. (1992) used a typical sequence of RSVP stimuli, but omitted the item immediately following the first target. In other words, there was a 100 ms gap, rather than another item following. Effectively, this meant that the degree of backward masking was reduced, and not surprisingly resulted in some improvement in the report rate for T1. Very surprisingly, it produced a considerable improvement in the reporting of T2; the AB effect had vanished (see Figure 4a). How did removing the mask for one target lead to an even larger improvement for another target that was yet to be presented? To return to our earlier analogy, if the shopkeeper is having some trouble in dealing with the first customer, then the second is kept waiting and suffers. That doesn't explain how the waiting queue suffers (if it were me I should probably chat to the person behind, and forget what I had come for), but that question was also addressed by removing items from the sequence.
Giesbrecht and Di Lollo (1998) removed the items following T2, so that it was the last in the list; again, the AB effect disappeared (see Figure 4b). So, no matter what was going on with T1, T2 could be seen, if it was not itself masked. To explain this result, together with the fact that making T1 easier to see also helps T2, Giesbrecht and Di Lollo developed a two-stage model of visual processing. At Stage 1, a range of information about target characteristics is captured in parallel: identity, size, colour, position and so on. In the second stage, they proposed, serial processes act upon the information, preparing it for awareness and report. While Stage 2 is engaged, later information cannot be processed, so has to remain at Stage 1. Any kind of disruption to T1, such as masking, makes it harder to process, so information from T2 is kept waiting longer. This has little detrimental impact upon T2 unless it too is masked by a following stimulus (I don't forget what I came to buy, if there is no-one else in the queue to chat with). When T2 is kept waiting it can be overwritten by the following stimulus. The overwriting process will be damaging principally to the episodic information; an item cannot be both white and black, for example. However, semantic information may be better able to survive; there is no reason why shoe and rope should not both become activated. Consequently, even when there is insufficient information for Stage 2 to yield a fully processed target, it may nevertheless reveal its presence through priming or EEG effects. There is an obvious similarity between this account and Coltheart's (1980) suggestion: both propose the need to join semantic and episodic detail.