
Privacy Risk Assessment
What is Risk?

Definitions of risk (adapted from Wikipedia):
- Source of harm
- Chance of harm
- Volatility of return
- Statistically expected loss
- Likelihood and severity of events
- Scenarios, probabilities and consequences
- Asset, threat and vulnerability
- Human interaction with uncertainty
- ...and many more
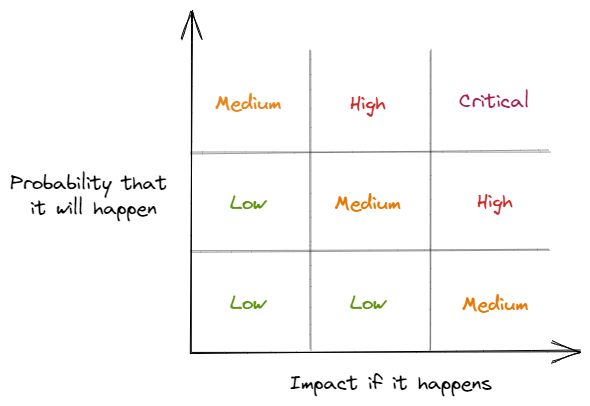
Risk is an ambiguous term, with very different meanings depending on the domain and who you ask. In economics, risk is the measurable probability of a loss, in contrast to uncertainty, which is not measurable. In security and privacy, we often think about the risk of a privacy harm as likelihood multipled by the impact if it does happen. As illustrated below, try to simply categorize risks rather than calculating scores for them. Often in your work, people will demand you provide them with numerical estimates of risk. But we need to resist the temptation to try to quantify everything, because usually these numbers are not meaningful at all. We have incomplete knowledge of the threat landscape, and we always will. The goal is simply to be able to make rough comparisons to help you prioritize your limited resources ("it's more important for us to work on mitigating risk A right now than risks B-E").
Radical Uncertainty
Why are numerical estimates so meaningless? In their book Radical Uncertainty: Decision-Making Beyond the Numbers, John Kay and Mervin King distinguish between knowable uncertainty, where we are able to gather information and then estimate probabilities, and radical uncertainty, which cannot be measured in any meaningful way and causes events that no-one ever anticipated. By all means try to gather useful information to reduce your uncertainty, but don't deceive yourself that you can estimate everything. We have a healthy dose of radical uncertainty to deal with in security and privacy (and in life in general).
We are emphasising the vast range of possibilities that lie in between the world of unlikely events which can nevertheless be described with the aid of probability distributions, and the world of the unimaginable. This is a world of uncertain futures and unpredictable consequences, about which there is necessary speculation and inevitable disagreement – disagreement which often will never be resolved. And it is that world which we mostly encounter - John Kay
Pair this insight with Lea Kissner's excellent talk on meaningless numbers, perverse metrics, and bad decision-making. She discusses one form of radical uncertainty, black swan events. She also provides examples of how her estimates of cost to the company (impact) varied from 0, to something that entirely coincidentally looked like a meaningful number but wasn't, through to values higher than the entire market capitalization of the company. How accurate are these estimates really? Are any of them meaningful?
USENIX Enigma 2023 - Invited Talk: Metric Perversity and Bad Decision-Making by USENIX Enigma Conference (2023). Hosted by YouTube.
Privacy Risk Assessment Methodologies
Given what you now know about meaningless estimates, you should approach quantitative privacy risk assessment methodologies with a healthy degree of scepticism. If you find yourself obsessing over calculating the perfect risk score based on a Monte-Carlo simulation, then you're just playing with meaningless numbers. Nonetheless, they can be useful. They can help you assess likelihood and impact in a structured way and provide guidance regarding which factors to consider. For example, if the personal data in question is sensitive personal data or the data subjects are from a vulnerable group, then we can expect privacy harms to be higher impact, so KU Leuven's PRA includes this as a factor. Some also factor in two core concepts we haven't discussed yet: your organization's risk tolerance (how much risk are they willing to accept?) and residual risk that remains even after mitigation efforts.
In general, try to factor in the cultural, political, and legal context where you can: this is one area where research can reduce your uncertainty. If you know your data subjects live in Ghana, for example, you can tailor your risk assessment accordingly. If you expect your data subjects to be located all around the world, keep vulnerable groups in mind. As we've discussed, personal data that is safe to share in one country might lead to abuse or imprisonment in another country. The remaining radical uncertainty, of course, includes the possibility that laws may suddenly change.
The table below is reproduced from Quantitative Privacy Risk Analysis by Cronk and Shapiro and compares four methodologies:
- Factor Analysis of Information Risk for Privacy (FAIR-P)
- KU Leuven Privacy Risk Assessment for Data-Subject Aware Threat Modeling (referred to here as KUL PRA)
- NIST Privacy Risk Assessment Methodology (NIST PRAM)
- CNIL Privacy Risk Methodology (CNIL PRM)
| FAIR-P | KUL PRA |
NIST PRAM | CNIL PRM | |
|---|---|---|---|---|
| Avoid | Solove's Taxonomy (or other normative privacy models)
|
Not explicit but discussed "hard privacy" of:
|
Problematic Data Actions:
|
Feared events:
|
| Likelihood | Frequency based on:
|
Frequency based on:
|
10-point ordinal scale | 4-point ordinal scale
|
| Severity | Magnitude based on:
|
Magnitude based on:
|
Cumulative 10-point ordinal scale based on organizational impacts:
|
4-point ordinal scale:
|
| Comments | Uses Monte Carlo simulations with Beta-PERT distributions for all factors. | Prioritization based on two-dimensional plot of likelihood and severity. | Prioritization based on two-dimensional plot of likelihood and severity |
Note that there are also many security risk assessment methodologies, for example the OWASP Risk Rating Methodology and Microsoft DREAD. These are worth investigating as, depending on your use case, they may be a better fit for you than the privacy methodologies above. While they can feel a little awkward for privacy use cases, they are much simpler and if your teams are already familiar with them it will make the transition to privacy threat modeling smoother.
Further Resources
- Radical Uncertainty: Decision-Making Beyond the Numbers - John Kay and Mervin King (2021)
- Quantitative Privacy Risk Analysis - R. Jason Cronk and Stuart S. Shapiro, Proceedings of the 2021 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW).